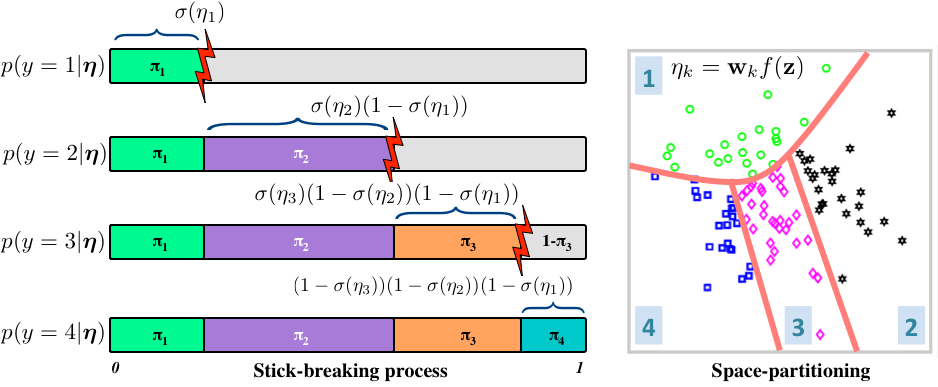
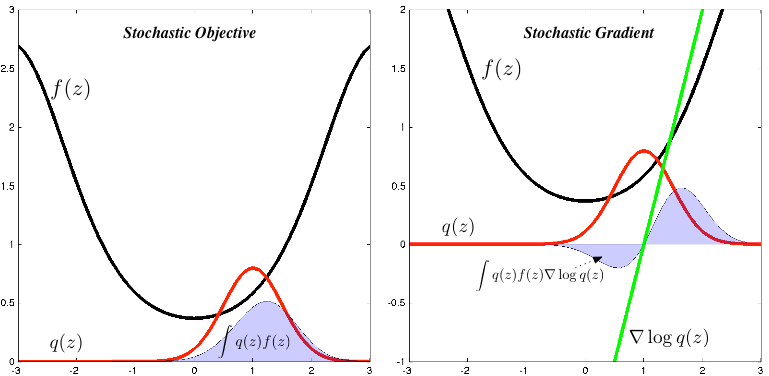
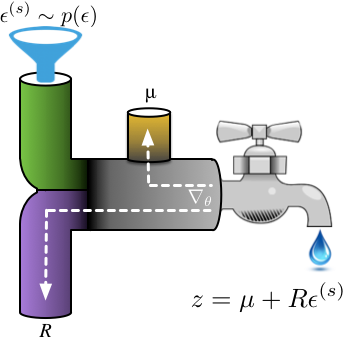
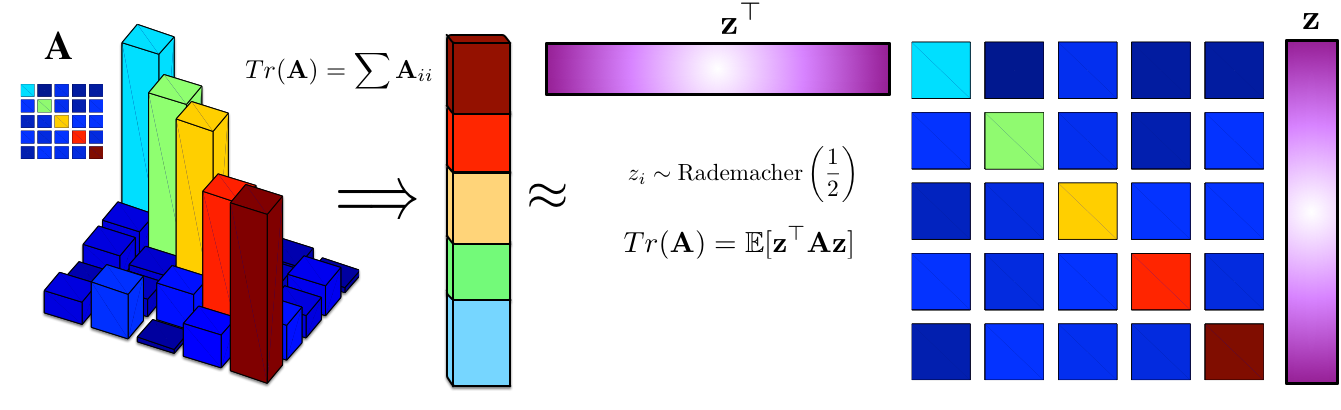
A Year of Approximate Inference: Review of the NIPS 2015 Workshop
[dropcap]Probabilistic[/dropcap] inference lies no longer at the fringe. The importance of how we connect our observed data to the assumptions made by our statistical models—the task of inference—was a central part of this year's Neural Information Processing Systems (NIPS) conference: Zoubin Ghahramani's opening keynote … Continue reading A Year of Approximate Inference: Review of the NIPS 2015 Workshop