'Tricks' of all sorts are used throughout machine learning, in both research and in production settings. These tricks allow us to address many different types of data analysis problems, being roughly of either an analytical, statistical, algorithmic, or numerical flavour. Today's trick is in the analytical class and comes to us from statistical physics: the popular Replica trick.
The replica trick [cite key="engel2001statistical"][cite key="sharp2011effective"][cite key="opper1995statistical"] is used for analytical computation of log-normalising constants (or log-partition functions). More formally, the replica trick provides one of the tools needed for a replica analysis of a probabilistic model — a theoretical analysis of the the properties and expected behaviour of a model. Replica analysis has been used to provide an insight into almost all model classes popular in machine learning today, including linear (GLM) regression, latent variable models, multi-layer neural networks, and Gaussian processes, amongst others.
We are often interested in making statements about the generalisation ability of our models; whereas approaches such as PAC learning provide for a worse-case analysis, replica analysis allows for statements in the average case that can be more useful, especially in verifying our numerical implementations. Replica analysis can also be used to provide insight into transitions that might occur during learning, to show how non-linearities within our models affect learning, and to study the effect of noise in the learning dynamics [cite key="seung1992statistical"]. This post aims to provide a brief review of the replica trick, the steps typically involved in a replica analysis, and links to the many ways it has been used to provide insight into popular machine learning approaches.
Replica Trick
Consider a probabilistic model whose normalising constant is Z(x), for data x. The replica trick says that:
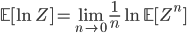
The left-hand side is often called the quenched free energy (free energy averaged over multiple data sets). The replica trick transforms the expectation of the log into the log of an expectation, with the result involving the nth-power of the normalising constant Z, i.e. the expectation is computed by replicating the normalising constant n times.
To see how we obtained this expression, we will exploit two useful identities.
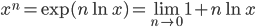
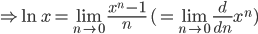
The application of this identity is often referred to as the replica trick, since it is what allows us to rewrite the initial expectation in its replicated form.
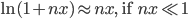
We can use these two identities to show that:
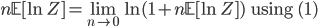
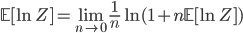
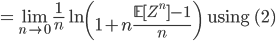
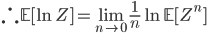
which is the identity we sought out. But this alone does not help us much since the partition function it is not any easier to compute. Part of the trick lies in performing the analysis assuming that n is an integer, and computing the integral n times, i.e. using n replicas. To compute the limit we do a continuation to the real line (and hope that the result will be valid). This final step is hard to justify and is one of the critiques of replica analysis.
Replica Analysis
Given the replica trick, we can now conduct a replica analysis, also known as a Gardener analysis, of our model[cite key="engel2001statistical"][cite key="castellani2005spin"]. This typically involves the following steps:
- Apply the replica trick to the integral problem (computation of average free energy).
- Solving the unknown integral, typically by the saddle-point integration scheme (sometimes known as the method of steepest descent). This will not always be easy to do, but certain assumptions can help.
- Perform an analytic continuation to determine the limit
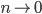 . This step (and the previous one) involves the assumption (or ansatz) of the structure of the solution, with the typical ansatz known as replica symmetry. Replica symmetry assumes that the replicas are symmetric under permutation of their labels. This is reasonable if we work with models with i.i.d. data assumptions where the specific allocation of data to any of the replicas will not matter. More advanced analyses make use other assumptions.
. This step (and the previous one) involves the assumption (or ansatz) of the structure of the solution, with the typical ansatz known as replica symmetry. Replica symmetry assumes that the replicas are symmetric under permutation of their labels. This is reasonable if we work with models with i.i.d. data assumptions where the specific allocation of data to any of the replicas will not matter. More advanced analyses make use other assumptions.
Following these steps, some of the popular models for which you can see replica analysis in action are:
- Binary Perceptron learning
- Linear (GLM) regression/perceptrons
- Multilayer (Bayesian) Neural networks
- Sparse Bayesian Classification
- Gaussian processes
- Factor analysis
- Sparse factor analysis
- Compressed sensing
Summary
One trick we have available in machine learning for the theoretical analysis of our models is the replica trick. The replica trick, when combined with an analytic continuation that allows us to compute limits, and the saddle-point method for integration, allows us to perform a replica analysis. This analysis allows us to examine the generalisation ability of our models, study transitions that might occur during learning, understand how non-linearities within our models affect learning, and to study the effect of noise in the learning dynamics. Such analysis provides us with a deeper insight into our models and how to train them, and provides needed stepping stones on our path towards building ever more powerful machine learning systems.
[bibsource file=http://www.shakirm.com/blog-bib/trickOfTheDay/replicaTrick.bib]
In your proof of the trick, i believe the ordering of what lemmas are used should be 2 then 1, rather than 1 then 2. The first statement follows from the log identity, right?