· Read in 8 minutes · 1499 words · All posts in series ·
[dropcap]This[/dropcap] trick is unlike the others we've conjured. It will not reveal a clever manipulation of a probability or an integral or a derivative, or produce a code one-liner. But like all our other tricks, it will give us a powerful instrument in our toolbox. The instruments of thinking are rare and always sought-after, because with them we can actively and confidently challenge the assumptions and limitations of our machine learning practice. Something we must constantly do.
One of the most common tasks we can attempt with data is to use features x to make predictions of targets y. This regression often makes a key assumption: any noise 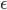 only affects the regression targets y (see figure 1(left)). In linear regression this is:
only affects the regression targets y (see figure 1(left)). In linear regression this is:
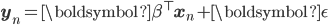
If this assumption is actually true for the problem we are addressing—that features x are linearly related to targets y using a set of parameters 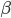 , and noise only affects the targets—then we can also call our model a structural model (or structural equation). Structural models can be used to make cause-effect statements, allowing us to use the model to make predictions about how actively controlling the features x affect the targets y. What if this is not true; it will often not be. We explore this question here, and develop one solution based on instrumental variables.
, and noise only affects the targets—then we can also call our model a structural model (or structural equation). Structural models can be used to make cause-effect statements, allowing us to use the model to make predictions about how actively controlling the features x affect the targets y. What if this is not true; it will often not be. We explore this question here, and develop one solution based on instrumental variables.
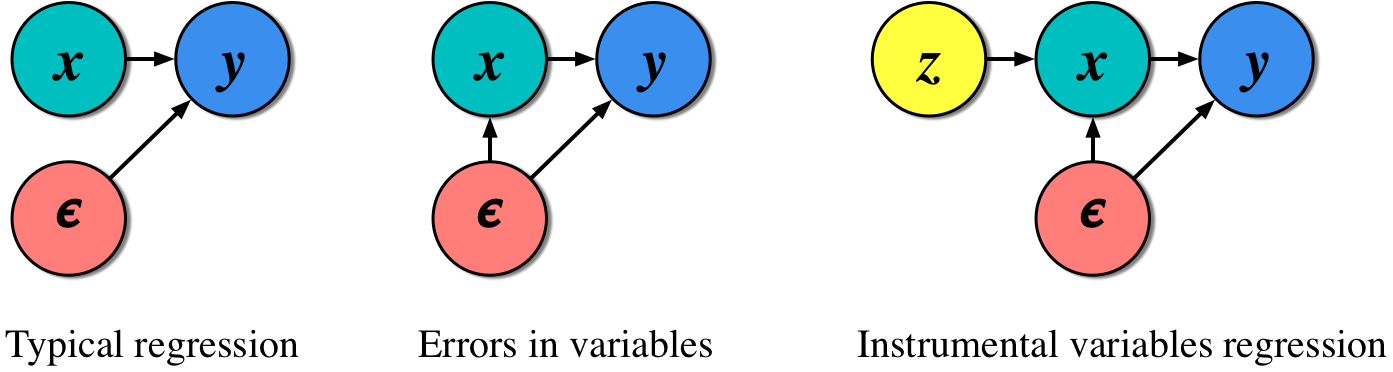
Figure 1. Three common regression scenarios.
Learning with Errors in Variables
Consider what is known as an errors-in-variables scenario1 (see figure 1 (centre)): a regression problem where the same source of noise affects the features and the target. Here, predictions of the target y are affected in two ways: directly through the variability in y, and indirectly through the effect on y that the noise affecting x has on it. This is generally an undesirable scenario.
If we ever find ourselves in this situation, then we no longer have a structural equation; any model we have will simply track correlations in the data and will leave us with biased predictions. This is where our trick of the day enters. The instrumental variables trick asks us to use the data itself to account for noise, and makes it easier for us to define structural models and to make causal predictions.
The instrumental variables idea is conceptually simple: we introduce new observed variables z, called instrumental variables, into our model; figure 1 (right). And this is the trick: instrumental variables are special subset of the data we already have, but they allow us to remove the effect of confounders. Confounders are the noise and other interactions in our system whose effect we may not know or be able to observe, but which affect our ability to write structural models. We manipulate these instruments so that we transform the undesirable regression in figure 1(centre) into a structural regression of the form of figure 1 (left).
For a variable to be an instrumental variable, it must satisfy two conditions:
- The instruments z should be (strongly) correlated with the features x. There should be a direct association between the instrument and the data we wish to use to make predictions.
- The instruments should be uncorrelated with the noise . This says that changes in instruments z should lead to changes in x, but not to y; otherwise z would be subject to the same errors-in-variables problem.
The common example is the prediction of future earnings (y) based on education (x). A person's ability () affects both their education and earnings, so is a confounder and source of common noise in this setting. There are many instruments we can find to satisfy the two needed conditions, meaning that there are no unique instruments. As instruments, we could use their mother's birth-month, the number of siblings they have, the proximity of the person to schools2, or even the person's month of birth3.
Two-stage Least Squares
The instrumental variables construction simply says that we should remove (marginalise) the effect of the variables (x) that have coupled errors, and instead consider the following marginalised distribution:
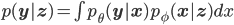
Where 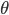 are the model parameters we are interested in learning, and
are the model parameters we are interested in learning, and 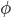 are parameters of a new predictor relating z and x. This integral suggests a very simple new type of regression algorithm that exploits the integral in two stages.
are parameters of a new predictor relating z and x. This integral suggests a very simple new type of regression algorithm that exploits the integral in two stages.
- Train a model to predict the inputs x given instruments z. This can be a regression model, or a more complex high-dimensional conditional generative model. Call these predictions
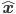 .
. - We now train a model to predict targets y given the predicted inputs .
If a linear regression model is used for both these steps, then we will recover the famous two-stage least squares (2SLS) algorithm. Using the closed form solution (the normal equations) for each stage of the regression, we get:
Stage 1: Feature prediction using instruments
- Optimal parameters:
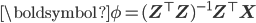
- Predictions:
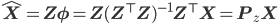
Stage 2: Target prediction using predicted features
- Optimal stage 2 parameters:
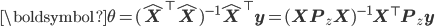
2SLS does something intuitive: by introducing the instrumental variable, it creates a way to eliminate the paths through which confounding noise enters the model to create an errors-in-variables scenario. Using the predicted inputs 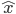 we recover a structural equation.
we recover a structural equation.
There are many powerful real-word examples where this thinking has been used, especially in settings where we cannot do randomised control trials but must rely on observational data. There is much more that could be written about these applications alone. Yet, how often will we have a situation in which we have an additional source of data to use as an instrument?
Instrumental variables are hard to find in real-world problems. And the assumption, hidden in the use of the Normal equations, that the number of instruments we use is the same as the number of input features (called the just-specified case), makes it difficult in high-dimensional problems. But the power of instrumental variables is not lost. They still shine, especially in settings where we control the definition of all the variables involved. One such area is reinforcement learning.
Reinforcement Learning with Instruments
It may not look like it, but the problem of learning value-functions is an errors-in-variables scenario. Our problem is to learn a linear value function using features 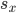 (when in state x) using parameters so that
(when in state x) using parameters so that 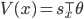 . The detailed derivations of what now follows are given in the paper by Bradtke and Barto (1996)4.
. The detailed derivations of what now follows are given in the paper by Bradtke and Barto (1996)4.
Let's start from the definition of the value function under transition distribution 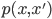 from state x to x', where a reward
from state x to x', where a reward 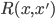 is observed upon transition and
is observed upon transition and 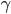 is a discount factor:
is a discount factor:
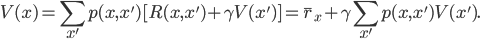
We can also rewrite the value function as an expected immediate reward 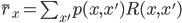 and an average next-state value. With this rewriting we will find a regression problem in plain sight. Let's first substitute the linear value function, and rewrite this equation in terms of
and an average next-state value. With this rewriting we will find a regression problem in plain sight. Let's first substitute the linear value function, and rewrite this equation in terms of 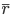 :
:
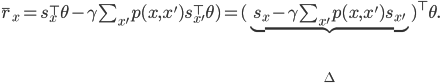
This is a regression from features that capture the change-in-state  to the average reward
to the average reward 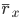 using parameters . It is also an errors-in-variables regression: both sides of the equation are affected by the same source of variability given by the unknown state transition dynamics .
using parameters . It is also an errors-in-variables regression: both sides of the equation are affected by the same source of variability given by the unknown state transition dynamics .
But we do have a trick for such scenarios: we can use instrumental variables regression and remain able to learn value-function parameters that correctly capture the causal structure of future rewards.
Because we control this setting, with a bit of thought, we can conclude that a set of instrumental variables that are strongly correlated with the features are the state features 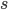 themselves. If we make this choice, we can apply exactly the two-stage least squares algorithm:
themselves. If we make this choice, we can apply exactly the two-stage least squares algorithm:
Stage 1: Instrumental variables regression
- Linear instrumental parameters:
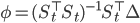
- Instrumental prediction:
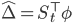
Stage 2: Average reward prediction
- Parameter estimation:
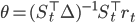
In reinforcement learning, this approach is known as Least squares TD (LSTD) learning. Most RL will instead reach this conclusion using the theory of Bellman projections. But this probabilistic viewpoint through instrumental variables means that we can think of alternative ways of extending this view.
We can go much deeper, and these papers can be used to explore this topic further:
- Tutorial in Biostatistics: Instrumental Variable Methods for Causal Inference
- Linear Least-Squares algorithms for temporal difference learning
- LASSO Methods for Gaussian Instrumental Variables Models
- Learning Instrumental Variables with Structural and Non-Gaussianity Assumptions
- Deep Instrumental Variables: A Flexible Approach for Counterfactual Prediction
Summary
The instrumental variables tell us to critically consider the assumptions underlying the models we develop and to think deeply about how to use their predictions correctly. The importance of this for our machine learning practice cannot be overstated.
Like every trick in this series, the instrumental variables give us an alternative way to think about existing problems. It is to find these alternative views that I write this series, and is the real reason to study these tricks at all: they give us new ways to see.
Complement this trick with other tricks in the series. Or read one my earliest pieces on a Widely-applicable information criterion, or a piece of exploratory thinking on Decolonising artificial intelligence.
Im a little confused and hope you could expand on a couple things:
1) The definition of an instrumental variable doesn't seem very clear to me. If you have variables which can predict y (in your example it was personal ability) that variable should be in the x block. It isn't an error estimator, it's a direct correlate to the y variable. I'm also unsure how it adds error to your x variable, as education and ability are different direct measurables.
In short, I don't see how this changes the simple linear regression equation. You may have variables with higher impact on y, certainly. You may also have noise in your measurements (e.g. white noise in a spectral dataset). Yet your description claws at something greater and I'm having a hard time seeing it.
2) is this math significantly different than a PCA or PLS calculation? You've pre-selected your z-variables (it seems) and then computed a y variable from this limited selection. I can't recall the math directly bur it seems quite similar.