Hutchinson's estimator [cite key='hutchinson1990stochastic'] is a simple way to obtain a stochastic estimate of the trace of a matrix. This is a simple trick that uses randomisation to transform the algebraic problem of computing the trace into the statistical problem of computing an expectation of a quadratic function. The randomisation technique used in this trick is just one from a wide range of randomised linear algebra methods [cite key='mahoney2011randomized'] that are now central to modern machine learning, since they provide us with the needed tools for general-purpose, large-scale modelling and prediction. This post examines Hutchinson's estimator and the wider research area of randomised algorithms.
Stochastic Trace Estimators
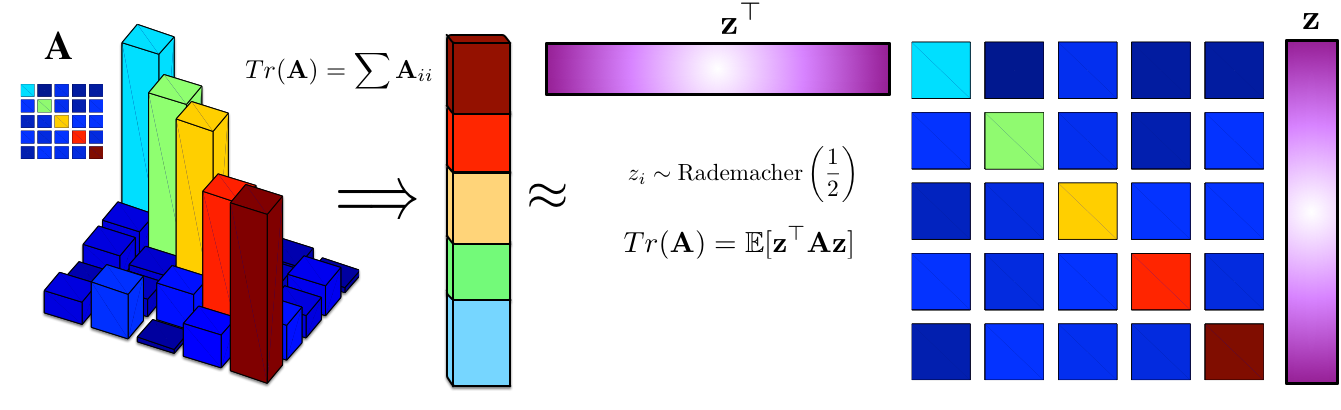
We are interested in a general method for computing the trace of a matrix with a randomised algorithm. Hutchinson's and other closely related estimators [cite key='hutchinson1990stochastic'] do this using a simple identity:
![\[Tr(\mathbf{A}) =\mathbb{E}[\mathbf{z}^\top \mathbf{A} \mathbf{z}]\]](https://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-58debe1838bf7fc2d971271fb09648bf_l3.png "Rendered by QuickLaTeX.com")
z is a random variable that is typically Gaussian or Rademacher distributed. We obtain a randomised algorithm by solving the expectation by Monte Carlo using draws of z from its distribution, evaluating the quadratic term, and averaging. This exposes an interesting duality between the trace and expectation operators.
Consider a multivariate random variable z with mean
![\[\mathbf{m}\]](https://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-50ec3f3a063c890eb490cefbf91139e4_l3.png "Rendered by QuickLaTeX.com")
and variance
![\[\boldsymbol{\Sigma}\]](https://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-a84e016fcbfb97b42e61e818a0b78ea7_l3.png "Rendered by QuickLaTeX.com")
. Using the property of expectations of quadratic forms, the expectation
![\[\mathbb{E}[\mathbf{z}\mathbf{z}^\top] = \boldsymbol{\Sigma} +\mathbf{m}\mathbf{m}^\top\]](https://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-31a5dc98acee77c343ae2ab5792e969b_l3.png "Rendered by QuickLaTeX.com")
. Furthermore, for zero-mean, unit-variance random variables, this implies that
![\[\mathbb{E}[\mathbf{z} \mathbf{z}^\top] = \mathbf{I}\]](https://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-2de78af10c6c96c557396608e4875e62_l3.png "Rendered by QuickLaTeX.com")
, which is what will enable our randomised algorithm. We can now easily derive this class of trace estimators ourselves:
![\[ Tr(\mathbf{A}) =Tr(\mathbf{A I}) =Tr(\mathbf{A\mathbb{E}[\mathbf{z} \mathbf{z}^\top]})\]](https://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-ddefacbd309f0e4b87b7b43b489ac25e_l3.png "Rendered by QuickLaTeX.com")
![\[= \mathbb{E}[Tr( \mathbf{A} \mathbf{z} \mathbf{z}^\top)] =\mathbb{E}[ \mathbf{z}^\top\mathbf{A}\mathbf{z}]\]](https://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-6877b23e26bd7f3c3ee74696996e799c_l3.png "Rendered by QuickLaTeX.com")
If you sample z from a Rademacher distribution, whose entries are either -1 or 1 with probability 0.5, then this estimator is known as Hutchinson's estimator. But we can also use a Gaussian or other distribution — our main requirement is the ability to sample easily from our chosen distribution.
Estimator variance
We have derived an unbiased estimator of the trace, and the usual next question that is asked is what we can say about its variance (low variance will give us more confidence in its use). We can compare the variance for the most commonly used random variables: the Rademacher and the Gaussian.
To derive the variance for the Rademacher distribution, we will need to exploit many of its properties. In particular, it has zero mean and unit variance. It is also a symmetric distribution, which implies that all its odd central moments are zero. Its 2nd central moment (variance)
![\[\mu_2 = 1\]](https://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-52fdf37e31b7970a1a9412468b1f0257_l3.png "Rendered by QuickLaTeX.com")
and its excess kurtosis is -2, which implies that its 4th central moment
![\[\mu_4 = 1\]](https://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-dc7fcc46cfd7b41be23c9dcd427ceb47_l3.png "Rendered by QuickLaTeX.com")
. All this is needed for us to use the expression for the variance of general quadratic forms [§5.1.2][cite key='petersen2008matrix']. Let
![\[\mathbf{a} = diag(\mathbf{A})\]](https://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-881458ed6273410e2227f195d64cae77_l3.png "Rendered by QuickLaTeX.com")
.
![\[\mathbb{V}[\mathbf{z}^\top\mathbf{A}\mathbf{z}] = 2\mu_2^2 Tr(\mathbf{A}\mathbf{A}^\top) + 4 \mu_2\mathbf{m}^\top\mathbf{A} \mathbf{m} + 4 \mu_3\mathbf{m}^\top\mathbf{A}\mathbf{a} + (\mu_4 - 3 \mu_2^2)\mathbf{a}^\top\mathbf{a}\]](https://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-c758f596449a9ed59f8e21220c449119_l3.png "Rendered by QuickLaTeX.com")
The 2nd and 3rd terms are zero because the mean m is zero. This simplifies the expression to:
![\[\mathbb{V}[\mathbf{z}^\top\mathbf{A}\mathbf{z}] = 2Tr(\mathbf{A}\mathbf{A}^\top) - 2 Tr(\mathbf{A})^2\]](https://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-c324d6d8afdb04305b2fd90db7226824_l3.png "Rendered by QuickLaTeX.com")
![\[= 2 \|\mathbf{A}\|_F^2 - 2\sum_i A_{ii}^2\]](https://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-c2cbb61381bf9686560a96f48c2ac77e_l3.png "Rendered by QuickLaTeX.com")
For Gaussian distributed z, the variance is easier (
![\[\mu_4 = 3\]](https://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-473d880c118323b590aa90942edee2f6_l3.png "Rendered by QuickLaTeX.com")
) and is:
![\[\mathbb{V}[\mathbf{z}^\top\mathbf{A}\mathbf{z}] = 2\|\mathbf{A}\|_F^2\]](https://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-2b080f923dc551de3b5bfaf08b5a5faa_l3.png "Rendered by QuickLaTeX.com")
The variance using the Rademacher distribution (Hutchinson's estimator) has lower variance compared to the Gaussian, and is one reason it is often preferred. We can also compute a bound on the number of samples needed by the Monte Carlo estimator to obtain an error of at most
![\[\epsilon\]](https://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-d7b18f78571c458e567622238f3c07ae_l3.png "Rendered by QuickLaTeX.com")
with probability
![\[\delta\]](https://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-a76fe1fbc21a84d903267c9e13d21e07_l3.png "Rendered by QuickLaTeX.com")
[cite key='avron2011randomized']:
- Rademacher:
![\[6 \epsilon^{-2} \ln \left(\frac{2}{\delta} Rank(\mathbf{A})\right)\]](https://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-00e6b8be8f4edf4f4ba267cff2e81a68_l3.png "Rendered by QuickLaTeX.com")
- Gaussian:
![\[20 \epsilon^{-2} \ln \left(\frac{2}{\delta}\right)\]](https://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-ccce8d23228cb94f870e40625041b64b_l3.png "Rendered by QuickLaTeX.com")
The story is different now and the Gaussian requires fewer samples. But these bounds are not tight, and many practitioners have found there to be little difference between the Gaussian and Rademacher cases.
Randomised Algorithms
Hutchinson's estimator shows one way in which randomisation and Monte Carlo can be used to reduce the computational complexity of common linear algebra operations. Hutchinson's estimator is widely used since trace terms are ubiquitous. Trace terms appear:
- When computing the KL divergence between two Gaussian distributions;
- When we compute derivatives of log-determinants, norms and many structured matrices, e.g., in the gradient of the marginal likelihood of Gaussian process models;
- When computing expectations and higher-order moments of polynomials of random variables.
As a concrete example*, a common problem that must be solved when optimising the marginal likelihood in Gaussian processes, is to compute
![\[Tr(\mathbf{K}^{-1} \partial \mathbf{K})\]](https://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-0c1967204a7b97a6f38d00f285f243db_l3.png "Rendered by QuickLaTeX.com")
. A direct computation has cubic complexity due to the inversion and matrix multiplication. We can reduce this complexity by using Hutchinson's estimator:
![\[Tr(\mathbf{K}^{-1} \partial \mathbf{K}) =Tr(\mathbf{K}^{-1} \partial \mathbf{K}\mathbf{I})=Tr(\mathbf{K}^{-1} \partial \mathbf{K}\mathbb{E}[\mathbf{z}\mathbf{z}^\top])\]](https://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-4ca6d9962fd4c8f4d31cff1962701292_l3.png "Rendered by QuickLaTeX.com")
![\[=\mathbb{E}[Tr(\mathbf{K}^{-1} \partial \mathbf{K}\mathbf{z}\mathbf{z}^\top)]=\mathbb{E}[\mathbf{z}^\top\mathbf{K}^{-1} \partial \mathbf{K} \mathbf{z}]\]](https://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-27d6473772fb8cef7a32094dd8d8c9ad_l3.png "Rendered by QuickLaTeX.com")
Computing an unbiased estimator of our initial trace problem can now be computed using only systems of linear equations, which is computationally cheaper than the direct method. One recent paper where this has been used for scalable probabilistic inference is [cite key='filippone2015enabling']:
The tool of randomisation that is exploited by Hutchinson's estimator is very powerful and can be used in many ingenious ways:
- Michael Mahoney [cite key='mahoney2011randomized'] provides some essential reading that covers the basics of randomised linear algebra, showing how we can solve least squares and matrix factorisation problems.
- The QR decomposition and SVD are core components of many machine learning algorithms, and there is much work that shows us how to scale-up these algorithms using randomised approximations.
- The celebrated Johnson-Lindenstrauß lemma (or flattening lemma) is widely known, and allows us to do randomised dimensionality reduction.
- This can then be exploited in many interesting ways, such as in compressed sensing or for scaling Bayesian optimisation.
- Randomised algorithms can be used for scalability across the machine learning pipeline. This is where randomised algorithms such as sketching, hashing and approximate nearest neighbours come into play. The book by Mitzenmacher and Upfal [cite key=mitzenmacher2005probability] is one very good introduction to this area.
Summary
Hutchinson's estimator allows us to compute a stochastic, unbiased estimator of the trace of a matrix. It forms one instance of a diverse set of randomised algorithms for matrix algebra that we can use to scale up our machine learning systems. A large class of modern machine learning requires such tools to handle the size of data we are now routinely faced with, making these randomised algorithms amongst our most welcome of tricks.
[*Thanks to Maurizio Filippone for introducing me to this trick.]
[bibsource file=http://www.shakirm.com/blog-bib/trickOfTheDay/hutchinsonsTrick.bib]
Hi Shakir,
Thanks for the post. I really like this short trick-explanation format.
I believe "V[z⊤ A z] = 2 Tr(A A⊤) − 2 Tr(A)^2" should be "V[z⊤ A z] = 2 Tr(A A⊤) − 2 Tr(A^2)"
EDIT: I commented too quickly! I believe it should be simply "-2 a^T a" rather.
Great post - just making a poster for the NCSML event in Edinburgh about our paper on a new stochastic trace estimator using mutually unbiased basis (https://arxiv.org/pdf/1608.00117v1.pdf). I'm definitely going to use a figure like yours to visually describe trace estimation so thanks for the inspiration!
Hi, would you please explain more about why "Computing an unbiased estimator of our initial trace problem can now be computed using only systems of linear equations, which is computationally cheaper than the direct method." works?
Nice post, I had never thought how randomized linear algebra could be useful to machine learning. Just two small nitpicks:
1) There is a missing "(" in V[z⊤Az)]
2) In the last equation =E[Tr(z⊤K−1∂Kz)], shouldn't the Tr disappear?
Pedro.
Both fixed - thanks! There are probably many ML problems where aren't yet exploiting the power of randomisation, so lots to do in this space.