
Keynote at Climate Informatics on 19 April 2023 in Cambridge.
Abstract: Generative models are probabilistic models of data that allow easy sampling and exploration of a data distribution using a learned model. In fields, like environment and climate, where access to samples allows for uncertainty representation, these models can provide a key tool to address the complex decision-making problems we I face. I'll begin with a high-level view of generative models as a field and how it has evolved. I'll then focus on the role of generative models in weather forecasting, looking at medium-range forecasting and nowcasting, which can serve as the basis for climate-focussed applications. A key aspect of these applications lies in how quality is assessed, and this will be a key focus of our discussion. I'd also like to touch on the sociotechnical implications of machine learning in climate, inviting a discussion of what shape ethical and responsible climate informatics currently takes. Advances in generative models can add value in the myriad of climate efforts we are undertaking, and my aim overall is to open a discussion as to what that ambitious research agenda looks like for us to take on together.

For today I put forward a title of ‘Generative Models for Climate Informatics’. I thought a broad and open title like this could set the tone for a more open discussion, and for your ongoing conversations throughout the conference about the types of approaches we should be investing in, to address all those key climate and environment research questions on the agenda this year. Now, generative models receive a great deal of hype these days. But I want us to see through that, to the real role they can have for the problems we tackle here. For almost the entirety of my research career, I have worked with generative models in some way, and for me, it was the area of climate and environmental science that finally and fully provided the compelling and socially-situated need for these methods. I won’t have any climate-focussed work to discuss today, and instead most of the results and provocations I use are in the weather domain. But there is a transferability and insight that i think is useful, and I’d like to hear during the discussion some of your experiences and applications across the breadth of climate-focussed applications, whether those are in downscaling, post-processing, stochastic parameterisations, attributions, severe events, tipping points, and so many other pressing research topics.
So back to the topic for today. For many of us, there will be several different motivators that influence what we work on and think about. Some people are responding to the drive for net-zero and the policy demands and insights needed to measure, track and achieve those goals. Others are directly responding to sustainability needs in energy and resource use, and the ongoing shift to renewables for example. Some are developing tools for climate adaptations and mitigations. And others see the key scientific gaps in our understanding and the urgency of that research in informing our global response to the climate emergency.
I think one aspect that ties these different motivators together is the role of probabilistic reasoning and uncertainty that is embedded within them all. This means that we need to keep investing in the tools of uncertainty and probability. And this is where generative models, as a rich set of tools directly for questions in probability and uncertainty enters, and why I want to focus on them today.
So our next 30 mins or so will be a journey across different aspects of the role of generative models, in 3 parts.
- There are many ways to think about generative models, so in part 1, I will give a high-level view of generative models as I see them. You might have a different view and it will be good for us to bring those views together in the discussion.
- Then in part 2, we’ll look at generative models for forecasting. I’ll give more focus to aspects of evaluation that will need our special care when working with generative models.
- And then in part 3, we’ll think about the sociotechnical implications of this work, to invite a discussion of what shape we think ethical and responsible climate informatics currently takes.
If I achieve my goals, we’ll have some fun thinking together about these topics, and we’ll reach the end with all of this fitting into a coherent whole.
Part 1: Generative Models
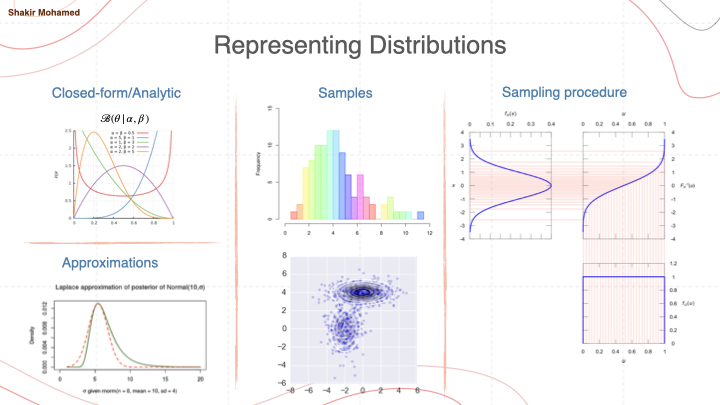
Let’s start with a little probability quiz. Quick fire question for you: how do you represent a probability distribution? Conveniently, modern probabilistic methods have given us many different approaches as an answer to a question like this.
Starting at the beginning, you can represent a distribution in an analytic form, like we do with many of the basic distributions, like those of the exponential family - Gaussians, categoricals, etc. We can also try our best to match complicated distributions by approximating them using the primitive distributions. We can also represent a distribution with a set of samples, like we would do with many Monte Carlo methods and as is done in ensemble systems. Or we could represent a distribution as a computational process by describing a sampling procedure, like the methods of sampling from a uniform and then applying the inverse cdf, or as is done in stochastic perturbation methods.
I’m reminding us of this topic of representing probabilities since, at its core, this is what generative models attempt to do: represent distributions. And all these same types of approaches are the foundations of this field.
Generative models in their simplest description are probabilistic models of data. But what we emphasise here is this word generative, which is the easy ability to generate or simulate samples from a distribution you have learned from data.
There are many reasons to be interested in having an ability to generate samples. In many current AI applications, this is about generating high-fidelity images or text. But for us in the physical sciences, this ability to generate samples from a distribution allows us to represent and explore uncertainty in the systems we study.
Generative models typically have a common high-level structure. Some source of randomness is transformed through a set of parameterised non-linear transformations to produce some data. You can also introduce an additional set of contextual, historical or side-information into this process. With this structure, the learning task is how to determine the values of the parameters that define the non-linear transformation.

In a different talk, at this point we’d dig a bit more into the probability theory in the construction of the probabilistic model. For today, let me directly jump to some different types of models that are commonly used. All the models I’m going to describe are parametric models, so are formed by sets of tunable parameters adjusted through numerical optimisation. I won’t touch on non-parametric models although they can have their own uses and advantages.
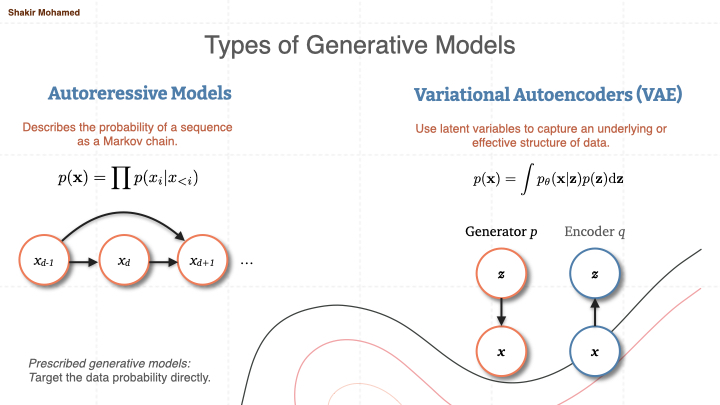
Autoregressive models
The first type of model is the autoregressive model. These are models formed through a markov chain, and you can describe the probability of a sequence straightforwardly. The arrows are nonlinear transformations, so they are not simply 1st-order autoregressive processes. And because the output nodes are known probability distributions, they can be sampled using the usual sampling process associated with those distributions, by sampling this chain sequentially. Many large text models you see today are of this form, and you sample the next token given what has come before and proceed until you sample a stop token.
Variational autoencoders
A second class of generative models introduce an unknown latent variable z that conceptually captures an underlying or effective structure of the data, which is then transformed into the data space x. To effectively use these models you need to know the posterior probability of these latent variables, so that is to know the probability p(z|x) . To achieve this Bayesian inverse process, we introduce an encoder model. The overall optimisation targets the marginal probability p(x) where the latent variables are integrated out. This will typically not be possible to do, so a bound is introduced and that is what is instead optimised.
Together, these two models are exemplars of what we could call prescribed probabilistics models, since they directly try to compute p(x) and likelihood functions, and use this measure of goodness to drive the parameter optimisation. But likelihood functions can in general be difficult to define, compute or use, so other methods avoid them and try other ways of assessing model goodness.
That leads to a third type of generative model.
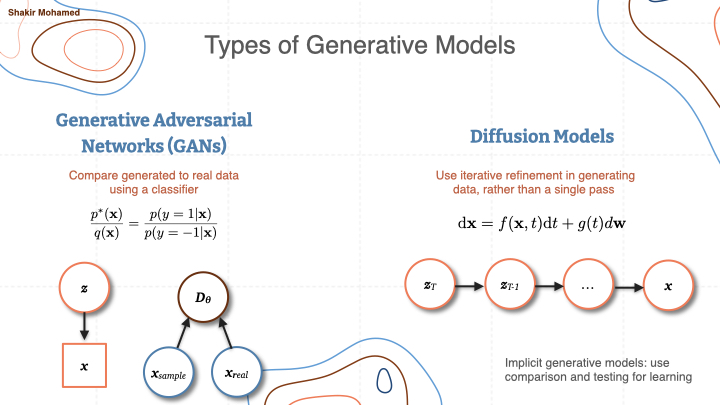
Generative adversarial networks
GANs have a latent generating process, like VAEs we just saw, that samples randomness once and then generates the data. Instead of computing a likelihood and using it for learning, GANs build a classifier that attempts to distinguish generated from real data, and the performance of the classifier becomes the learning signal.
Diffusion models
Finally diffusion models, have a generating process that looks the same as VAEs and GANS at a high-level. But they have a probabilistic structure that generates multiple sets of randomness, so instead try to do iterative refinement in generating data, rather than generating data in a single pass. At training they also don’t compute a likelihood, but exploit the structure of the probabilistic model to instead compute the gradient of the log-probability that can be more easily computed —we refer to this as the score in statistics —and this is what guides learning.
Using your background, you might see similarities and equivalences to these generative models, perhaps using an entirely different language or set of inferential techniques. And that i think is an exciting opportunity for the ongoing mutual exchange between all these different fields.
Good models, of course, require good data, good engineering and good evaluations. The recent focus for these model types has been on how to handle larger amounts of data and the improvements that come with being able to learn more data. Today these models are generating compelling long-from text, generating high-quality images and audio, and being used to create various forms of digital assistants. But they are also creating many concerns about fair data use and ownership, misinformation, and responsible innovation.
So this is what we too have to contend with. When we make use of generative models, we too will gain new tools to learn complex high-dimensional data, like the types of geo-spatiotemporal data many of us work with, to see them work at large scale, and to be able to sample from them easily. That opens up new opportunities - but also opens up new risks.
I hope that will be enough as a review for now so i’ll end this brief review at this point, so we can instead dig a bit deeper into some of the uses of generative models in spatiotemporal data and beyond. So onto:
Part 2: Generative Forecasting
Having skimmed some titles of what is on the agenda this week, there are a few weather scale-problems that are being discussed here over the next few days, and this is the area that I’ll get more into detail on. While these problems might not be ones you are studying, there is increasing awareness and need for integrated weather and climate systems to meet the resilience and sustainability goals we have set for ourselves, as scientists and through global cooperation. Technically, the types of problems, solutions, and concerns that arise in weather will be similar to the problems in other areas, and so can be a guide for more general considerations in the use of generative models.
I want to start with a deterministic forecasting problem, because I want to emphasise what an exciting phase of research we are entering where machine learning and numerical predictions meet - this is an amazing convergence and I think will help these fields open new frontiers.
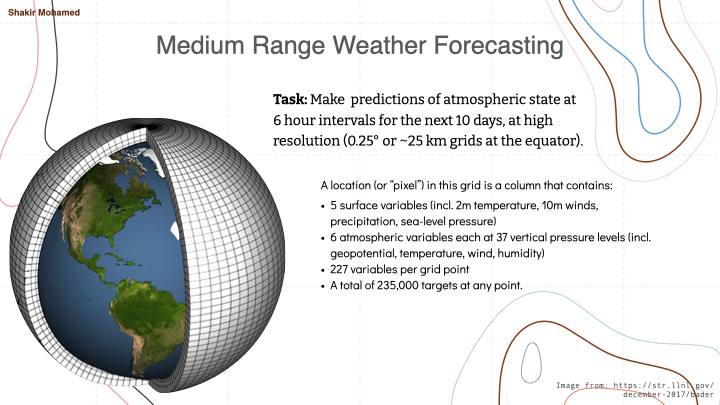
The problems of medium range global weather forecasting are about predictions of atmospheric state up to 10 or 15 days into the future. Predictions in this area are truly one of the incredible feats of science and numerical and statistical forecasting. Weather predictions are ones we all rely on every day, directly or indirectly, and with applications wherever we have commercial, industrial or social needs. Machine learning is making significant inroads into this area.
In our own work, the prediction problem involves making predictions in 6 hour intervals from 6 hrs to 10 days ahead, at around 25 km spatial resolution at the equator. In the data we used, each “pixel” in this grid on the earth contains 5 surface variables, along with 6 atmospheric variables each at 37 vertical pressure levels, for a total of 227 variables per grid point. So that means 235k variables for each time point we want to make a prediction for. The aim here is to build the best general-use weather model we can. This general model is then later used or customised by other users, like environmental agencies or commercial users, for their specific problems. And these problems are many: renewable energy, logistics, outdoor event management, flood forecasting, emergency services, and so many more.
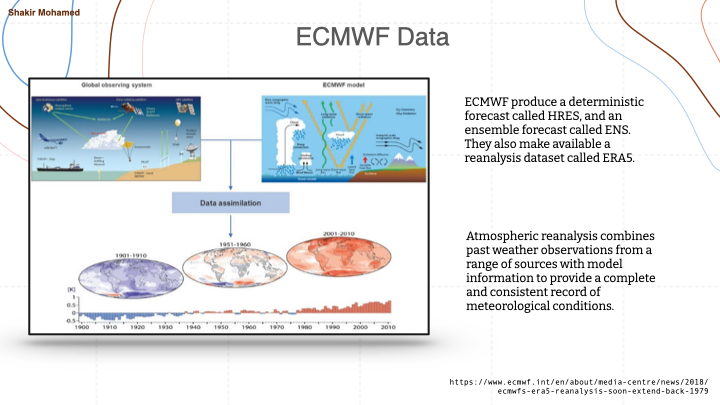
It is widely accepted that the world's best medium range forecasts come from the European centre for medium range forecasting. They produce a deterministic operational forecast called HRES, and an ensemble forecast called ENS. They also make available a reanalysis dataset called ERA5. The data for training machine learning models uses this reanalysis dataset. And since we are interested in creating operationally-useful models, we test our model by comparing to forecasts from the operational system using the HRES data - of course being very careful about how we make these comparisons.
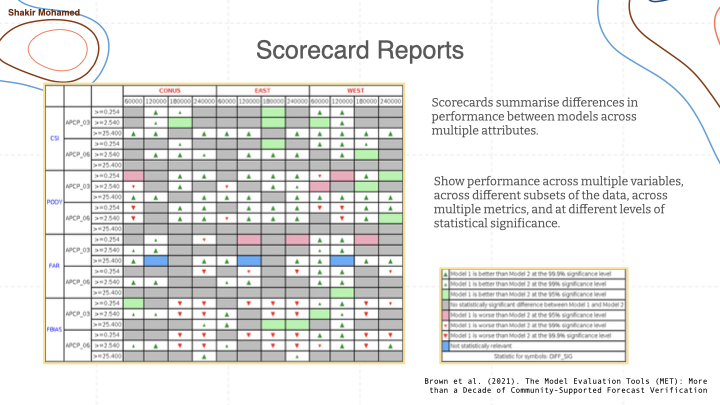
To tell the story of skillful performance, we make as many types of predictions as we can, and verify the forecasts using as many different forms of comparison as possible. One thing that researchers in atmospheric science do so well, is to report performance using a scorecard. These scorecards visually summarise performance across different variables, and using different metrics. Importantly, they also show performance across different subsets of the data, like performance for the southern hemisphere vs the northern hemisphere, or other important subsets of the data. This scorecard shows what this can look like. One thing that is important is that it shows performance relative to a strong baseline, usually the current system used in operations, and indicates statistical significance at different levels (99.9%, 99%, 95%).
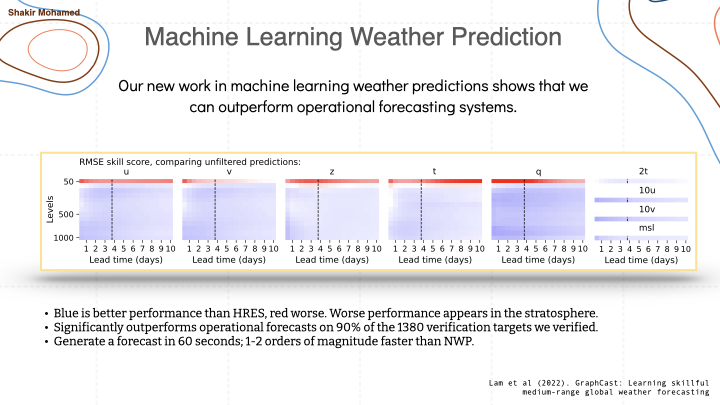
And here is a scorecard for our own work, that shows that machine learning can outperform operational weather systems. This scorecard allows us to affirmatively answer that long-standing question on whether data-driven machine learning approaches for weather forecasting can be competitive with world-leading operational forecasting systems. Using graph neural networks, we are able to show state-of-the-art performance that significantly outperforms the most accurate operational deterministic global medium-range forecasting systems on 90% of the 1380 verification targets we assessed. Our model can generate a forecast in 60 seconds on a single deep learning chip, which we estimate is 1-2 orders of magnitude faster than traditional numerical weather prediction methods.
I don’t want you to leave with the impression that this is a replacement for NWPs or the role of physical knowledge and simulation. Rather, what’s clear from all the different contributors and groups working in this area, is that rapid advances are being made in the use of data-driven machine learning. We are seeing this in improvements compared to operational weather forecasting, and we hope this is part of opening up new ways of supporting the vital work of weather-dependent decision-making that is so important to the flourishing of our societies. And I expect that we will make further advances as we move from deterministic to probabilistic methods.
Communicative tools like the scorecard that show complexity, but in manageable ways, will be essential as we continue to advance these types of methods. This approach to evaluations is an area where machine learning is itself learning from the atmospheric sciences, and where mutual advances will continue to unfold.
One use of these types of predictions is in the management of renewable energy, especially since the biggest impact in reaching net zero will come from decarbonisation by electrification. Those who work in renewables will know that when renewable energy is used, grid operators need to keep reserve amounts of energy available to balance the energy grid, and this reserve comes from fossil fuels. Energy from wind turbines is a vitally important source of carbon-free electricity, especially here in the UK and across Europe, and the cost of turbines has plummeted and adoption has surged. But Wind energy is unreliable. Better predictions in this area can allow uncertainty in wind energy output to be used in the energy mix scheduling and provision on the grid. This in turn can allow for more fine grained control of energy reserves, allowing for the real outcome we hope for - a reduction in the amount of fossil fuels required for grid balancing.
Better predictions of wind, typically 2-3 days in advance, which is right within the medium-range forecasting regime, can help better schedule these renewable sources, increasing their value for operators. And when used for problems faced by operators, we see the beginning of new approaches for managing these renewables. In the particular case shown in this slide, a simple predictive model of wind speeds allowed for an increase in the economic value of wind when tested in a real system.
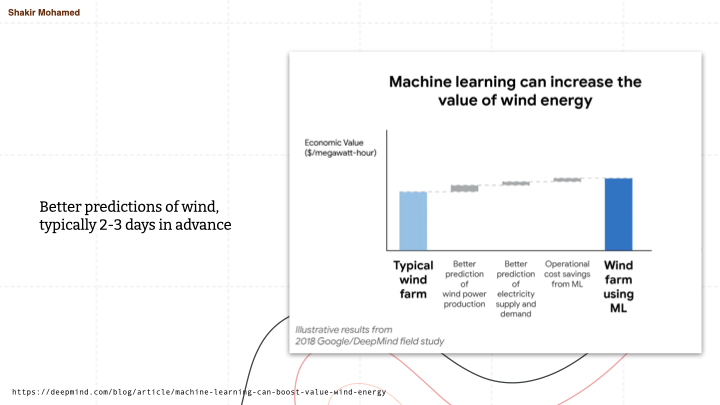
The problems in medium range forecasting i’ve just covered did not use generative models and were not able to quantify uncertainty or provide large-member ensembles. This ability can provide a great deal of value, so I want to switch to a related problem that shows this advantage clearly.
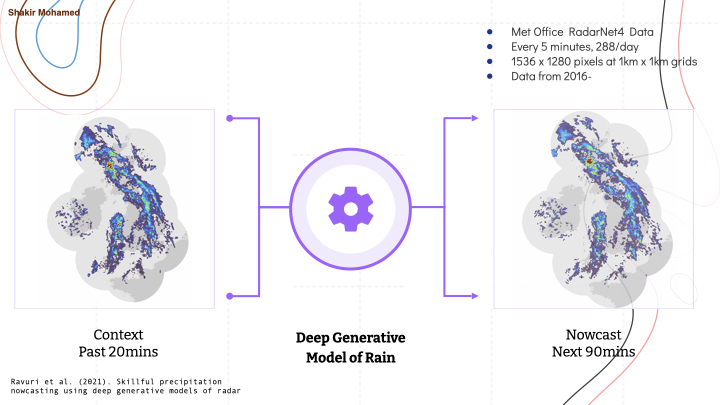
The problem of Nowcasting is all about very short term rainfall predictions: the type of next-hour predictions of rain you find on many weather apps today. In many countries, there are ground stations that use radar to measure the amount of moisture in the atmosphere. For example, the UK has radar that covers 99% of the country and provides data at 1km resolution (and even lower up to 200m), and available every 5mins. For 1km data, this gives us data that looks like an image of size 1000 x 700 pixels, where every pixel is the accumulated moisture level in units of mm/hr.

This is also one of the perfect problems for generative models, since we need tools to generate realistic looking radar data, and a critical need to generate many samples to report the uncertainty of possible future rainfall. We eventually developed a highly competitive approach using generative adversarial networks. GANs here are well suited to generating high-resolution and realistic radar images which is needed to match the resolution of the tools that experts already use, and can generate samples rapidly allowing large ensembles to be created - it took about a second to generate every nowcast in our approach.
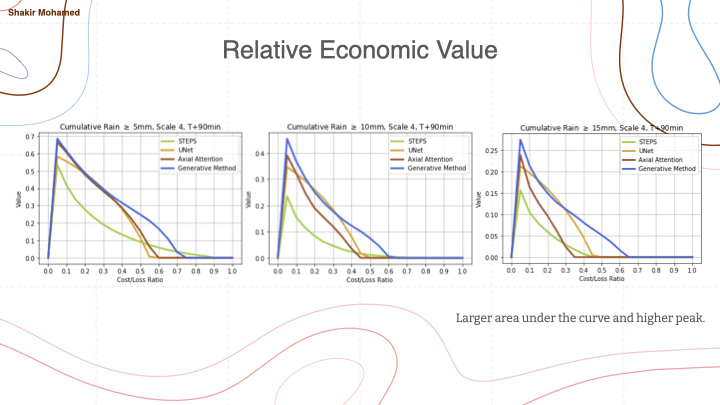
Although I expect that you don’t need convincing that more ensemble members are useful, we were able to quantitatively demonstrate the benefit of probabilistic predictions in this setting using a simple and widely used decision-analytic model. This model shows the economic value in the decision to take a precautionary action or not in response to certain rainfall thresholds. As you can see here, this model allows us to vary the number of samples used, and shows a clear increase in value when 20 ensemble members are used, compared to one sample, which effectively matches the deterministic case. Where better is seen by the larger peak and the greater area under the curve.
And when you use this relative economic value approach to compare to other methods, comparing to 3 other methods on this slide, we are able to show in one way that taking a generative approach to nowcasting is able to provide the best forecast value.
Overall, the approach to demonstrating value that we took was shaped by the real-world needs of expert forecasters and expert meteorologists. This is important because there are many different types of impact you can have when making weather predictions.
In nowcasting, we could have impact by focusing on every day consumer needs, e.g., in creating the best weather app. That would lead us to focus on problems that emphasise making good predictions of low-rainfall, because as everyday people, our needs are more about rain or no-rain.
Or, we could focus on the other end, on the needs of meteorological experts and operational users, who care primarily about heavy rainfall, because it is heavy rain that most affects everyday life, and where the protection of life and property matters significantly.
Ideally we can do both, but our focus on the needs of experts and the role of crucial decision-making information meant that throughout our work, all our metrics of performance had an emphasis on heavy rain - the top 10% of rainfall events. That in turn influenced how we thought about our models and how we worked with the data. It is also for this reason that we focussed on predictions up to 90mins, since this is the time window for action in operational settings.
The conclusion from our collaboration with expert meteorologists, both researchers and those who work in operational forecasting centres, was clear: for nowcasting to be useful in operational-uses the forecast must:
- Provide accurate predictions across multiple spatial and temporal scales;
- Account for uncertainty and be verified probabilistically;
- And perform well on heavier precipitation events that are more rare, but more critically affect human life and economy.

As we move to the wider use of generative models though, the question of how we carefully evaluate these methods and provide evidence for any conclusions must remain central. And i’d like to draw your attention to some areas in need of scrutiny. In machine learning, because we have a focus on generalisation and generality by learning from data, our methods can often extrapolate outside of the domain of the training data in unusual or undesirable ways. In the physical sciences for example, there will be an implicit role of conservation laws, and we might not account for those in purely data-driven predictive systems. We quickly discovered that when deep learning meets weather, the performance of different methods can be difficult to distinguish using traditional forecasting metrics: metrics need to have enough resolving power to help distinguish meaningful differences in our predictions and samples. These metrics can’t account for all the ways that we might ‘cheat’ in making predictions with ML. For example methods could make more blurry predictions as a way of spreading uncertainty, or can add high frequency noise, or can be physically inconsistent as you accumulate over space. As a result, the bar for providing comprehensive evaluations of machine learning for weather and climate problems must remain high.
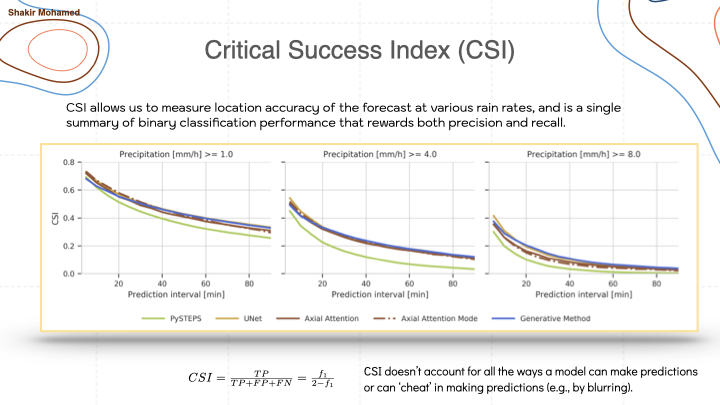
One of the common metrics is called the critical success index (CSI), which evaluates binary forecasts of whether or not rainfall exceeds a threshold t,and is a monotonic transformation of the f1 score. It can show that deep learning methods can outperform existing approaches, at the time the most competitive approach was known as PySTEPS, which is an optical flow approach. But this metric doesn’t help show differences between deep learning approaches that you see with all the clustered lines on this graph.
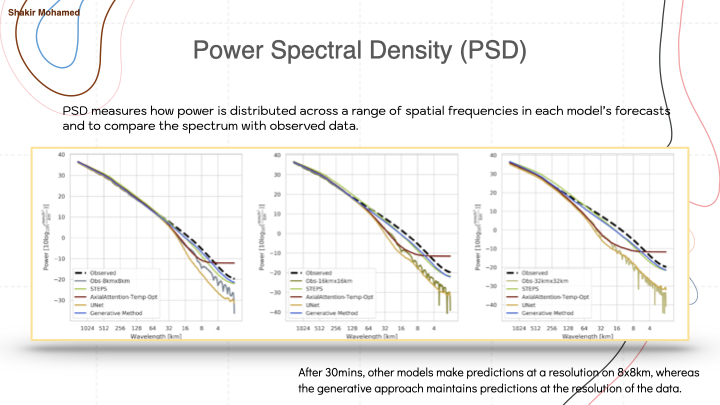
To add to this analysis, we can compare the power spectral densities of different predictions - we want predictions to match the spectrum of the data. It shows us blurring, and the introduction of high-frequency noise from many deep learning methods. After 30mins, other models make predictions at an effective resolution of 8km x 8km, whereas the generative approach maintains predictions at the 1km resolution of the data.
Since we are interested in probabilistic forecasts, we can show the continuous ranked probability score (CRPS), and compute it over several spatial scales, to show that generative models in this application provide competitive and consistent forecasts across spatial scales.
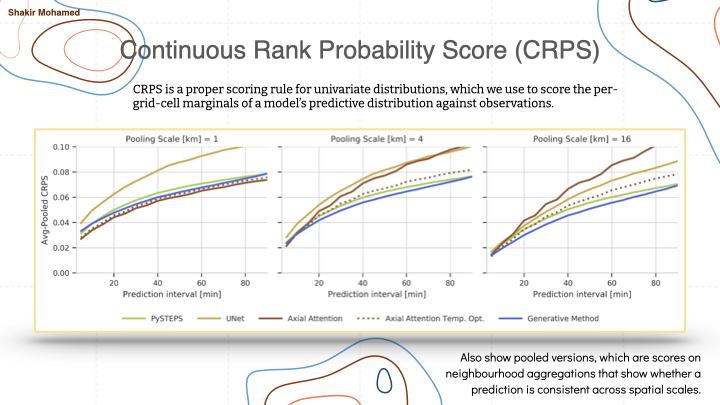
When you look at these together, and also add several other evaluations, you can tell the story of a role of generative models in creating a new generation of nowcasting approaches by showing that the forecast quality and forecast consistency of our method was performing better, in statistically significant ways, than competing approaches.
Here you can see what some radar data looks like, and how different methods compare. This is a case study of a very challenging rainfall pattern over eastern Scotland and the observed data. This case was also chosen by the chief forecaster at the UK Met Office, who were our collaborators in this work, who was able to give us a test chosen independently of our project team.
- We compared to the incumbent method called PySTEPS based on optical flow.
- And also compared to the ever-popular UNet approach, which we also later incorporated into the generative model.
- And here is another popular deep learning approach.
- And finally here is the performance of our generative model approach.

Because weather forecasting is used by expert decision makers every day, and the fact that we were working with expert meteorologists, this was an opportunity to include their judgements as part of the assessment of this generative approach. And this is what we did. Experts who were working in the forecast centre, were asked to take part in 2 phase evaluation study.
With their participation, we showed that almost 90% of the experts in our study preferred the generative approach compared to alternatives, and in this way we were able to demonstrate the ability of generative models to provide improved forecast value. And using interviews, it was easy to provide evidence that the experts were making informed and reasoned judgements of performance and preference based on meteorological insight, and were not fooled by things like visual realism of the generative models we were using.
This is what some of them had to say:
- “I like things to look slightly realistic even if they’re not in the right place so that I can put some of my own physics knowledge into it.”
- “This looks much higher detail compared to what we’re used to at the moment. I’ve been really impressed with the shapes compared with reality. I think they’re probably better than what we’re currently using. The shapes in particular, some of them do look really high resolution”

As I wrap up this section, its no surprise to you by now that I think there are many impactful applications on the horizon for generative models in weather and climate. Our conversations about digital twins continue and generative models can be a great tool in this area; we continue to seek tools for stochastic parameterisation in climate models to account for lack of knowledge at unresolved scales; and we continue to seek new probabilistic tools and early warning systems for severe events, amongst so many other important directions.
There is a lot of opportunity, but that also means also a lot of work for us to do together. For my final section, allow me to shift the tone of our discussion. So on to:
Part 3: Sociotechnical Climate Informatics
Nowcasting is a very good problem to look at as some ethical and social assessments of the role of AI and machine learning. One comfort many researchers take is that environmental data are not measurements directly derived from the social world, with the implication that many of the challenging social problems we’ve seen in other areas of machine learning, like algorithmic racism or misinformation, are perhaps fortunately avoided. And while this is the case for many sources of data, like the radar data we were just considering, we must continue to exercise caution.
No technical system exists outside or independently of the social world and the people involved in those systems. So it is better to think of them as sociotechnical systems, where we recognise that the social and the technical are woven and interwoven together at every level of operation. Environmental data sets and benchmarks have an imprint of human choice by the people who create them. We can create smart grids, but these grids and the behaviours they regulate are social worlds and have implications for the lives of real people, especially since energy poverty and the challenges of changing climate fall disproportionately on the racialised and already poor, who often don’t benefit from the types of technical interventions we are talking about. And predictions we might provide, whether it is about grids or the weather, are about how people interact with the world and so can shape the behaviours of decision-makers, which itself a responsibility that can’t be taken lightly.

Even before I dig further into this part, what I would love you to take away as homework, is to later answer two questions: How is your technical work shaped by social factors? How does your work try to shape society? So I'm asking what shape, do you think, ethical and responsible climate informatics currently takes.
Coming back to nowcasting. The same nowcasting ideas that can be used for rainfall to support flood predictions and responses, can also be used to predict other phenomena like sandstorms. The countries of south west Asia experienced many serious sand storms in the past few years affecting people's health and daily lives. Yet uses for sand storm predictions is directed to planning military functions.
The nowcasting problem, as I described it, depended heavily on the high quality data of the UK radar network, as does most of machine learning research. That type of data will not be available for most of the world. So in this sense, the problem and approach to nowcasting I described is very much a “first world problem”, and is not a solution that is applicable to most of the world.
And it isn’t hard to find other areas in need of new forms of ethical and responsible climate informatics. Our drive for greater green energy through wind turbines has led to the interference of the reindeer migration and the dispossession of the indigenous Sami people in northern Norway. Windfarms necessitate the building of roads and other infrastructure, often in areas that were previously undisturbed by humans, and reindeer simply don’t go to places where there are turbines. As the Sami leaders so clearly say: The Sámi people are not the ones who have contributed the most to climate change, but we seem to be the ones who have to carry its greatest burden.

We also see other dispossession dynamics that exist in climate policy. Most policies and sustainability schemes have been largely shaped by the environmental agendas of the Global North—the primary beneficiary of centuries of climate-altering economic policies. These policies can take very little account of ways of living or practicalities of people in Global south countries, nor are they regularly involved in the development of such policies. So as our work engages with these forms of policy design, we should continue to consider our position and whose concerns and knowledge we choose to amplify or ignore.
As a last exemplar concern. Working towards net zero is not only a good thing for our climate, but also makes a very strong business case. As new net zero processes, technologies and institutions are created, scaled and refined, they will become a large part of the economy of the future; creating new opportunities for exporting net-zero technologies to those that don’t have them, while creating jobs and wealth in the countries that do.
In all these examples, we are asking who’s benefits are being protected. Whom are regulatory norms and standards designed to protect—and who is empowered to enforce them. What attitudes of benevolence and paternalism are at play in how we conduct our research. And what other, more participatory and inclusive approaches might we take instead. These are fundamental questions that emerge from taking a sociotechnical view of our field.
These concerns might once have seemed purely for the realm of politics and policy, but these are the concerns that are facing those who develop generative models and AI in other areas, today, and so ones we must also contend with.
But I don’t bring this up to remove the excitement of new research in this area and the opportunities that are on the horizon. I do so only to invite everyone to expand the sets of concerns you include in how you advance your work. There is an entire growing area of machine learning now on these topics, as well as decades of research from so many other areas of sociotechnical scholarship that we can all build on.
Wrapup
So let me end here, with my deep thanks to you all. If I’ve achieved my aims, then you will leave this talk with two key takeaways:
- Firstly, we are seeing exciting advances in machine learning in environmental sciences. And generative models that allow us to generate many samples and represent uncertainty are a key part of those coming advances.
- Secondly, there is a need to expand the breadth and rigour of our evaluations. We should continue to hold machine learning using probabilistic and other forms of verification and assessment to a high standard. And we should also expand our scope of thinking to be more than technical, but to also be sociotechnical.
Thank you so very much for the opportunity to put forward some of this research and provocations to you today. Being in meetings like this continues to be one of the great joys for me as a scientist, and I’m excited for the rest of the conference and the things we will learn over these three days.

As a short postscript, here are some resources to followup on:
- One of the most comprehensive sources on all topics probabilistic, Kevin Murphy’s 2 volume book, Probabilistic Machine Learning.
And some work I have been able to be part of with many amazing collaborators over the years:
- Our paper on predicting and evaluating rainfall forecasts, Skillful precipitation nowcasting using deep generative models of radar.
- A newer paper, GraphCast: Learning skillful medium-range global weather forecasting.
- And finally, a philosophical and theoretical paper on our responsibilities, Decolonial AI: Decolonial Theory as Sociotechnical Foresight in AI.
Again, my deep thanks to you all.