Keynote for the 40th International Conference on Machine Learning (ICML 2023). Links to the Video, and Slides (pdf, 30MB).
Abstract: This talk talk has a single objective: to advocate for machine learning infused with social purpose. Social purpose here is an invitation to deepen our inquiries as investigators and inventors into the relationships between machine learning, our planet, and each other. In this way, social purpose transforms our field of machine learning: into something that is both technical and social. And my belief is that machine learning with social purpose will provide the passion and momentum for the contributions that are needed in overcoming the myriad of global challenges and in achieving our global goals. To make this all concrete, the talk will have three parts: machine learning for the Earth systems, sociotechnical AI, and strengthening global communities. And we’ll cover topics on generative models; evaluations and experts; healthcare and climate; fairness, ethics and safety; and bias and global inclusion. By the end, I hope we’ll have set the scene for a rich discussion on our responsibility and agency as researchers, and new ways of driving machine learning with social purpose.

Aloha, Hello! I’m still amazed to actually be here in this gorgeous part of the world. And also how amazing to be at this 40th ICML. Allow me to dive straight in: my aim today is simple: to amplify and accelerate the work of machine learning with social purpose. Social purpose here is an invitation to deepen our inquiries as investigators into the relationships between ML, our planet, and each other. So social purpose will make machine learning something that is both technical and social. And ML with a social purpose will provide the passion and direction for our field’s contributions towards overcoming those many global challenges and in achieving our shared prosperity.
Before I continue, let me say a little about myself. My name is Shakir Mohamed, and, like many of you, I’m a curious bee in this flowery meadow we call machine learning. I have many different roles, and I have shifted my focus many times over the years. Today, I give attention to work in weather and climate, science and society, diversity and equity, and global community building, and I hope to share all of these in some form with you today.
But most importantly, I’d like to express how humbled and energised I am to be here on this stage and with you all today. I think the evidence will show that I was moulded as a machine learning researcher at this conference, in these poster sessions, at these workshops, sitting where you are. For any of the work I've been lucky to be involved in and that I might be able to say has had some impact in our field, they were published here, at ICML. So it is a big thing for me to stand here before you all today, and I’d like to express my gratitude to all the organisers for this opportunity, and to all of you here in this audience, in-person, online, or whenever you might be seeing this.
Enough about me, back to the topic for today. There are three reasons you should give me your full attention for the remainder of our session:

- Firstly, I’ll give you evidence that probabilistic machine learning should continue to be a core investment area for us as a research community. When generative models are connected to research in the Earth Systems in particular, we create all the pathways to impact we want: we uncover fundamentally new questions, we are led to building new products, and we connect our work to pressing needs: all propelled by social purpose.
- Secondly, I will emphasise that we undertake research in technology and society together: so calling for us to deepen a sociotechnical AI research portfolio. Taking this path can give you new tools to debunk flawed thinking, allow you to move beyond any sense of helplessness in times of technological volatility, and gather the ingredients that place our work on stronger ethical foundations: all distinguished by social purpose.
- Thirdly, I want to offer you an answer to the question of whether we can make AI truly global. A more global field and industry can shift machine learning to be more general: magnifying social purpose.
So that’s our talk in three parts: ML for the earth systems, sociotechnical AI, and global and general machine learning; and hopefully this will all make sense as whole when we get to the end.
To be more playful and connect with some wider history, I’ve entitled each part after an influential book to provide further thoughts for you beyond my core message — of machine learning with social purpose. So onto:
Part 1: Worlds in the Making
I’m using here the title from Arrhenius’s book to provoke your thoughts about the earth as a system, and the tasks of simulating, forecasting, predicting, projecting the future worlds we might experience, or the ones we might never see.
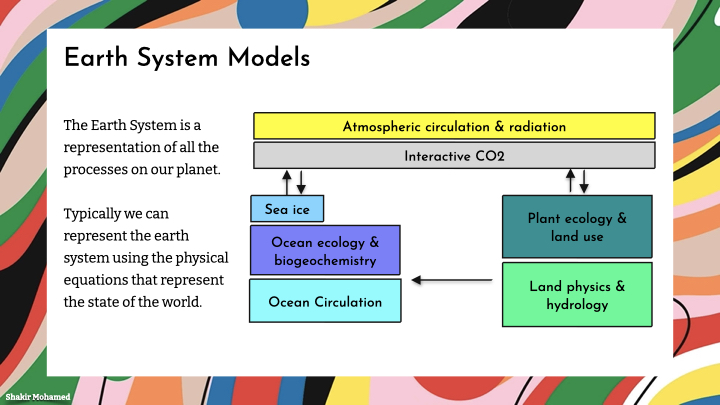
The Earth System is a representation of all the processes on our planet. That includes the clouds and rain, the wind and sun, the oceans and land. Typically we can represent the earth system using the physical equations that describe the state of the world. Earth system models are everywhere: they are of course the tools that continue to deepen our understanding of this changing planet we inhabit; and they are central to our ambitions to live sustainably together. So in this part, I invite you to dedicate some of your time and work towards research in machine learning for the earth systems. I will share some of the exciting developments in this area where there are many opportunities for global collaboration, and expose some of the technical, and social challenges we face.
The modelling of weather and climate processes is a marvel of science. These models are general in their uses and directly inform decision-making across sectors. Decisions are taken by people, and the social purposes of weather and climate modelling are made clear when we look at what those decisions are. And one common framework is to decompose these decisions along the prediction horizon that is used.
- There are many critical decisions that support emergency services planning, flood response, outdoor event planning, or other activities where the protection of life and property is urgent. These typically depend on regional predictions that are 1-2 hours ahead, which is referred to as nowcasting.
- Yet, other decisions need more advanced notice. Load balancing on power grids where power generation is spatially and temporally optimised, management of renewable energy sources, and national weather operations work on time scales from a day up to 10 days ahead. This requires medium-range forecasting, that makes predictions of all atmospheric phenomena and typically across the entire earth.
I’ll focus on these two timescales, but there are others important timescales, namely, Sub-seasonal to seasonal (S2S), Decadal climate forecasting, and, multi-decadal projections or simply climate projections.

Nowcasting
Nowcasting is the short term prediction of atmospheric phenomena, usually a single variable, up to 2 hours ahead. You can do nowcasting of many variables, like rain, sunshine amount, air quality, or other variables. Of special interest is rainfall nowcasting: the type of next-hour predictions of rain you find on many weather apps today.
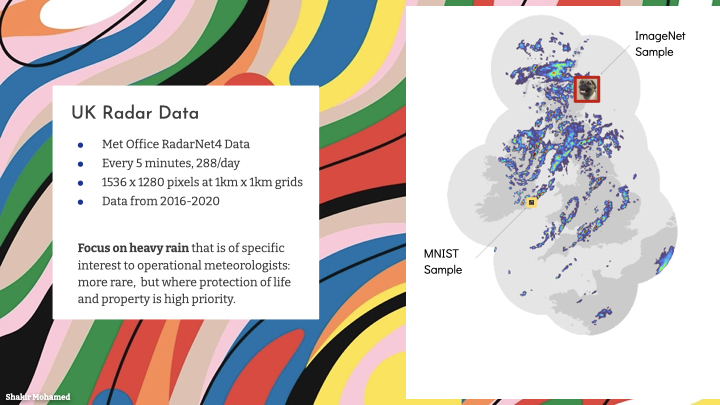
Rainfall nowcasting relies on data from ground station radar networks that measure the amount of moisture in the atmosphere. This remote sensing and data collection is a key investment for many countries. For example, the UK has radar that covers 99% of the country and provides data at 1km grid resolution (and even lower up to 200m), and is available every 5mins. The radar network for the contiguous US covers 73% of the landmass and 94% of the population. By 2025, all of India should be covered by radar.
The data from a radar feed is like a video, where pixels in each frame are the accumulated moisture level in units of mm/hr.
Predictions of rain for us as everyday consumers is important, but the prediction product we explored, focused on the nowcasting needs of meteorological experts and operational users. They care primarily about heavy rainfall, because it is heavy rain that most affects everyday life, and where the protection of life and property matters significantly. Specifically this means to serve this social purpose, new nowcasting methods will need to show performance, that is, should have forecasting skill, on the more rare, heavy-rain events - the top 10% of rainfall events. And this skill should extend out to 90mins, since this is the time window for action in operational settings.
This is also one of the perfect problems for generative models. Generative models allow us to produce new types of probabilistic models and forecasts of the earth system, and are quickly becoming one of the most active and productive areas of research and operations today.
We eventually developed a highly-competitive approach using generative adversarial networks. To give you an understanding of what this looks like, this is a case study of a very challenging rainfall pattern over eastern Scotland. This case was chosen by the chief forecaster at the UK Met Office, who was able to give us a test case chosen independently of our project team.
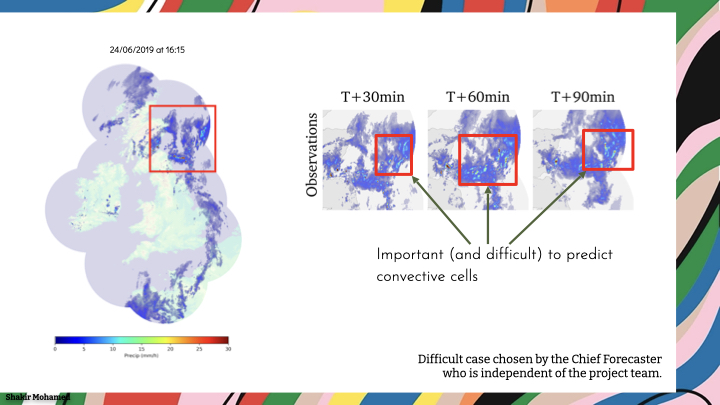
The incumbent method for nowcasting was based on optical flow, and is a method called STEPS. This approach can produce very sharp predictions, but it cannot account for the rapid dissipation and appearance of rain, what is known as convective rain.
As a quick aside, finding ways to communicate science concepts, whether about AI generally, or on a topic like how rain works, is needed for the trust we want to establish for our social-purpose work . It was a wonderful opportunity to work with a popular YouTube channel called Minute Earth to do exactly this; so I’d recommend checking their channel out, and in particular the video on rain and nowcasting.

Coming back to our comparison. We evaluated several other Deep Learning methods. They were deterministic, so had issues with blurring, or an inability to match reality well. What you see here is for a u-net. And this is for a different method showing a different type of blurring. And finally here is our GAN-based approach, referred to here as DGMR. The sharpness and realism of rainfall patterns is something that stood out for this method.
We mainly worked with data from the UK, but we also applied it to radar from the US, which allowed us to assess wider applicability and limitations when using different measurement systems and different data sources.

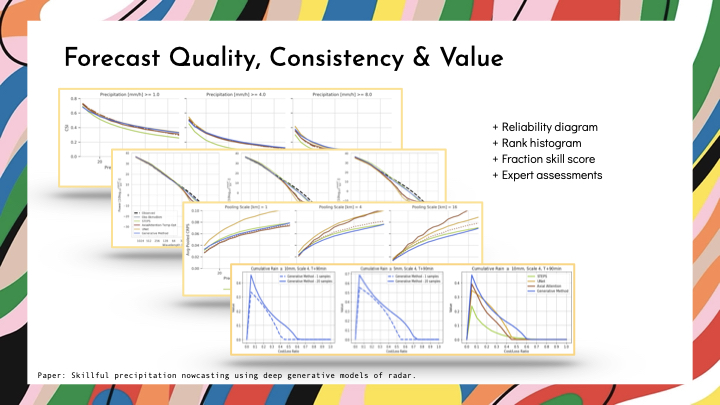
Looking at generated images and videos, while satisfying, isn't a rigorous or acceptable form of evidence for the new role of machine learning for the earth systems. The skill of a forecasting system is multifaceted, so there won’t be a single leaderboard metric to focus on. Instead comprehensive evidence is essential and makes the problem of generative model evaluations amongst the most important.
We quickly discovered that when deep learning meets weather, the performance of different methods can be difficult to distinguish using traditional forecasting metrics. These metrics can’t account for all the ways that we might ‘cheat’ in making predictions with ML. For example, methods often make more blurry predictions as a way of spreading uncertainty, or can add high-frequency noise, or can be physically inconsistent as you accumulate over space. As a result, the bar for providing comprehensive evaluations of machine learning for weather and climate problems remains high.
One of the common metrics in the field is called the critical success index (CSI), which evaluates binary forecasts of whether or not rainfall exceeds a threshold t, and is a monotonic transformation of the f1 score. It can show that deep learning methods can outperform existing approaches, like STEPS that was the most competitive approach at the time. But this metric doesn’t help show differences between deep learning approaches that you see with all the clustered lines on this graph.
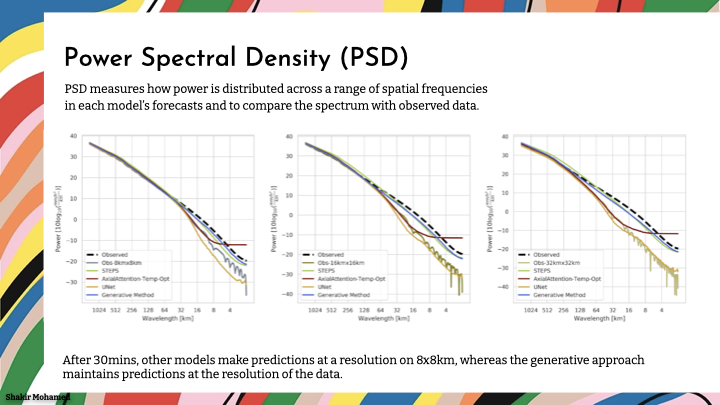
To add to this analysis, we compared the power spectral densities of different predictions - we want predictions to match the spectrum of the data. On this graph, we want the samples to match the black line. It shows us that models are blurring, and the introduction of high-frequency noise. After 30mins, other models make predictions at an effective resolution of 8km x 8km, whereas the generative approach maintains predictions at the 1km resolution of the data.
Since we are interested in probabilistic forecasts, we can show the continuous ranked probability score (CRPS), and compute it over several spatial scales, to show that generative models in this application provide spatially consistent probabilistic forecasts.
We also quantitatively demonstrate the benefit of probabilistic predictions in this setting using a simple decision-analytic framework. As a metric we evaluate the relative economic value in the decision to take, or not to take, a precautionary action in response to different rainfall thresholds. As you can see here, this metric allows us to vary the number of samples used, and shows a clear increase in value when 20 samples are used, compared to one sample that is the deterministic case. Where better is seen by the higher peak and a greater area under the curve.
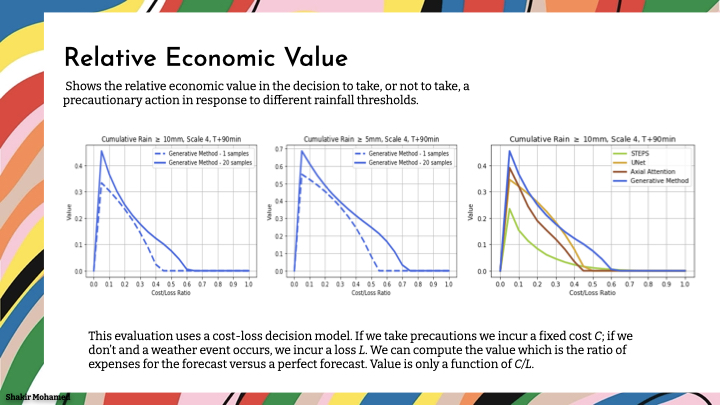
Finally, alongside all these measures (and a few more), we dug deeper into the value of our forecasts by working with communities of expert decision makers who work with these tools every day. We had to dive into the methods of cognitive assessment, and psychology, and interview methods, and designed an assessment protocol for expert meteorologists working in the forecast centre.
Using expert participation, we were able to show that almost 90% of the meteorologists in our study preferred the generative approach compared to alternatives. And using interviews, it was easy to provide evidence that the experts were making informed and reasoned judgements of performance and preference based on meteorological insight, and were not fooled by things like visual realism of the generative models we were using.
This is what some of them had to say:
- “I like things to look slightly realistic even if they’re not in the right place so that I can put some of my own physics knowledge into it.”
- “This looks much higher detail compared to what we’re used to at the moment. I’ve been really impressed with the shapes compared with reality. I think they’re probably better than what we’re currently using. The shapes in particular, some of them do look really high resolution”

When you look at all the evidence together, you can tell the story of the role of generative models in creating a new generation of nowcasting that improves forecast quality, forecast consistency, and forecast value. And I’m excited to see so much new research in nowcasting already improving on what I’ve shown here and conducted by research groups across the world.
Global Forecasting
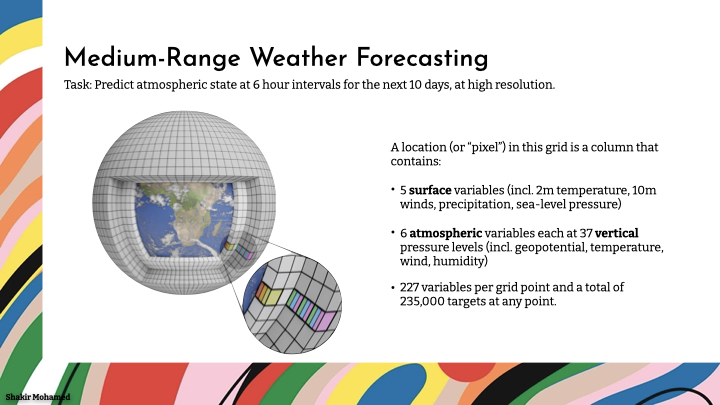
The Earth system contains many more phenomena than just rain, so let’s move beyond forecasting a single atmospheric variable and over a local region, to making global forecasts of the entire state of the atmosphere. We want these predictions up to 10 days ahead, which is known as medium-range forecasting. Weather predictions in this area are ones we all rely on every day, directly or indirectly, and with applications wherever we have commercial, industrial or social needs. Machine learning is making significant inroads into this area.
In our work, the prediction problem involves making predictions in 6 hour intervals from 6 hrs to 10 days ahead, at around 25 km spatial resolution at the equator. In the data we used, each “pixel” in this grid on the earth contains 5 surface variables, along with 6 atmospheric variables each at 37 vertical pressure levels, for a total of 227 variables per grid point. So that means 235k variables for each time point we want to make a prediction for. The aim here is to build the best general-use base weather model we can. This base model is later built upon by other users, like environment agencies or commercial operations, for their specific problems. And these problems are many: renewable energy, logistics, aviation, safety planning and warnings, and so many more.
It is widely accepted that the world's best medium range forecasts come from the European centre for medium range forecasting, and they make this data easily available for researchers. Using numerical simulation, the ECMWF produces a deterministic operational forecast called HRES. They also make available a reanalysis dataset called ERA5. Reanalysis data is produced by correcting a forecast after it has been made using observations to provide the best description of the state of the atmosphere. So reanalysis is the process of Kalman or state smoothing that we would do for any latent variable dynamical systems after observing data to update the latent state. The data for training machine learning models uses this reanalysis dataset. But since we are interested in creating operationally-useful models, we test our model by comparing to operational forecasts using the HRES data - of course being very careful about how we make these comparisons.
To tell the story of skillful performance, we again make as many types of predictions as we can, and verify the forecasts using as many different forms of comparisons as possible. So what you are seeing on the slide is known as a scorecard, which visually summarises model performance across different variables, and using different metrics. Importantly, they also show performance across different subsets of the data, like performance for the southern hemisphere vs the northern hemisphere, or other important subsets of the data.
This scorecard shows that machine learning can outperform operational weather systems. And so with this scorecard, we can now affirmatively answer that long-standing question of whether data-driven machine learning approaches for weather forecasting can be competitive with world-leading operational forecasting systems.
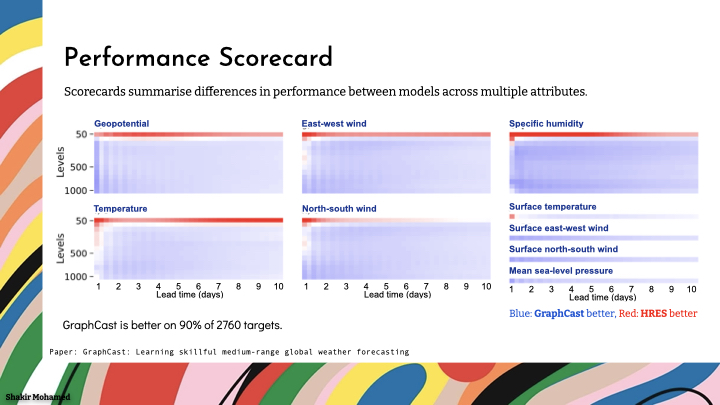
Using graph neural networks, we are able to show state-of-the-art performance that significantly outperforms the most accurate operational deterministic global medium-range forecasting system on 90% of the 1380 verification targets we assessed. Our model can generate a forecast in 60 seconds on a single deep learning chip, which we estimate is 1-2 orders of magnitude faster than traditional numerical weather prediction methods.
I don’t want you to leave with the impression that this is a replacement for widely used numerical weather prediction methods, or the role of physical knowledge and simulation. Rather, what’s clear from the results of so many different contributors and machine learning groups across the world working in this area, maybe some of you in this room, is that rapid advances are being made in the use of machine learning for weather. We are seeing this in improvements compared to operational forecasts and across forecast horizons, and we hope this is part of opening up new ways of supporting the vital work of weather-dependent decision-making that is so important to the flourishing of our societies. And we expect that advances will continue as more of you join this effort and add your intellectual energy to this exciting research area.
More To Do
This part was all about showing that as a research community we are collectively making progress: in generative models for earth systems and forecasting, in comprehensive evaluations, in better science communication, in better informing global policy, and infusing machine learning with social purpose. But there are many impactful research directions waiting to be picked up, like
- Better precipitation forecasts, which is a key priority since most models are weak here.
- Seasonal and decadal forecasting, which have been so poor historically that there are few applications.
- Predictions for renewables, digital twins, and net-zero.
- Causal methods for detection and attribution of significant events.
The opportunities are many.
So far our social purpose was directed to work in machine learning research. That work is often driven by our imaginations of how a model or technology can be used by societies; and an imaginary of tech for good. So let’s unpack those imaginations a bit more; onto:
Part 2: Dreamscapes of Modernity
We are now going to focus on sociotechnical thinking in AI, and this characteristic of social purpose.
Equity in Forecasting
Forecasting, in particular, exposes a set of social considerations that can deepen our understanding of the drive for social purpose. So consider who actually gets to benefit from improved forecasts.
The nowcasting problem, as I described it, depended on the high quality data of the UK radar network. That type of data will not be available for most of the world, so at the outset, I know that this is not a tool for the majority world. Although I would like it to be, this reality of the world constrains what can be done, and requires me to be more humble in any claims to effectiveness in this area.
This Lack of applicability and exclusion is one concern, but negative outcomes from forecasting are more common than you’d think. In NE Brazil and Zimbabwe, better rainfall forecasts were created to benefit poor and vulnerable farmers. Instead, better forecasts were used by bank managers to protect themselves, denying credit to farmers who would otherwise have received it, and putting these farmers at greater risk. In Peru, the improved forecast of El Nino and the prospect of a weak season gave fishing companies an incentive to accelerate layoffs of workers. Sadly, a negative pattern that emerges, is that better models lead to greater harm and vulnerability.
Sociotechnical AI
What should be clear from my emphasis on decision-making, applicability, and harms, is that no technical system exists outside or independently of the social world and the people involved in those systems. This two way interaction between technical considerations and social considerations, is what is referred to as a sociotechnical approach. Whether you see machine learning and AI as a science, a discipline of engineering, an area of investment, source of extreme risk, or as a strategic advantage, the starting point for a sociotechnical foundation of our field is an understanding that the social and the technical are enmeshed, entangled and interwoven at all levels.
So with this foundation, sociotechnical AI is all about adjusting and adapting the conceptual apertures we use as we go about our work: asking our technical and engineering work to account for a wider and more expansive set of considerations; while also bringing focus and manageability to the seeming vastness of social considerations. Sociotechnical approaches ask for an ecosystem view, and is a way of engaging with that ecosystem.

A Sociotechnical Stack
So I want to leave you today with a model with which to consider the holistic ecosystem in which machine learning operates. What I’d like you to now imagine is a stack, and to use that image specifically to explore AI’s sociotechnical stack. I’m playing with this idea of the full stack, which is one of those powerful images of modern software engineering.
As a first draft, perhaps we can think of this stack as having several thematic layers. There is a level for research, commercialisation and deployment, governance, another for co-operation and community. What this stack should do is to help us see how wider social considerations and different expertise mix with technical questions. And exposing these different levels gives us new areas for research, ways of taking responsible actions, and advocating for change and social purpose.
Let’s try to fill out this stack with things we might already know. For the research level, there are things we might already be doing,
like the focus on bias in data, assessments of fairness and environmental impacts, improved documentation practices, and reporting the limitations of research outputs. We have created new journals and research institutes, and disciplinary boundaries are being blurred where the vital insights from the humanities and sociology are becoming blended with machine learning, adding a different form of technical expertise, and a contextual and systematic understanding of innovation to our research.
For the deployment level, our tools to integrate privacy and fairness are improving, consent and the role of research ethics committees is maturing, we undertake third-party audits, and have more mechanisms of red-teaming, bug bounties, and external oversight. New practices on data sharing, sandboxing and interoperability, and watermarking and provenance, are becoming available. And more focus on licensing and codes of conduct are becoming the norm.
At the governance level, we have seen widespread codification of AI ethics principles. The rights of workers involved in AI ecosystems–from those who label data, those who might write the code, or do the last mile delivery–continues to be a key area of concern. Comprehensive evaluation that includes safety, factuality and cultural inclusion, and that allows consistent comparison across models and services, are being developed. And over these past few years, attention has shifted to questions of formal technical standards, compliance, certification, and regulation.
And finally at a level of community and cooperation, we have more ways of including people into our designs, whether it looks like citizen science, co-design, a citizens jury, or a deliberative forum. This is vital since our work in AI safety is incomplete without the inclusion of the people who are meant to be kept safe. We have made important strides towards diversity, equity and inclusion, but the work of AI for global benefit with distinctly non-global representation and engagement still concerns. And there is growth in wider social safeties, like organising, unionising, and grassroots community-building; alongside new thinking about protected disclosures and whistleblowers. And at the international level, there is greater focus on human rights, how people enjoy their rights to scientific advancement, and driving social purpose based on our global goals for sustainable development.
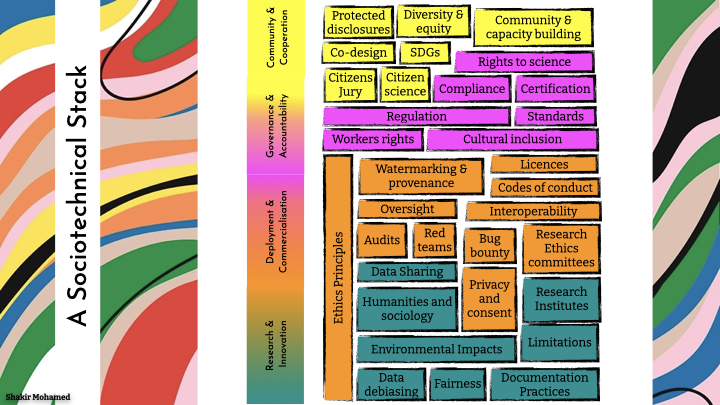
Participation
Many of my efforts are focussed on thinking and tools for the community-level of this stack. Here we are asked to recognise forms of expertise beyond the purely technical, and that the experiences and views of those people who are vulnerable and stand to be most affected by our work, alongside those who will benefit, is a form of deep expertise that we can bring into our technical work. We refer to this as participation.
But as it stands, community participation and input in our work is minimal. Yet, participatory approaches for AI are on the rise. Participation though, does not mean using people, like raters or annotators to evaluate our methods or provide better preference data — that is not a form of participation. Participation means including people in the design of our methods, being comfortable with disagreement, and being open to changing what we work on, and how we work, based on wider input. Participation changes the nature of how we research, design and evaluate ML systems, making it people-centred, and turns it into an ongoing process. Participation done well can place our work on stronger ethical foundations by incorporating and accounting for the values of the societies we operate in.

More To Do
As a research community we are making progress by taking an ecosystem view of our field and expanding our understanding of the sociotechnical stack, driven by broad participation, and social purpose. But there are many new insights still needed, like
- Establishing further participatory and community-centred work to showcase and enable their effective use
- More work on human-AI interactions, behavioural studies and evaluations.
- More historical and decolonial work that continues to provide public memory that stimulates greater rigour and humility.
- Evolving practices for documentation, standards and testing, verification and monitoring, data rights and sovereignty, and social and democratic influence.
And the list goes on. I do have one final section. So on to:
Part 3: The Human Condition
In this part, i want us to shine more light on the varieties of people-centred approaches in machine learning.
Empirical Likelihood
As we think about those people-centered approaches in our groups, now is a good time to detour to remind you that social purpose does provide momentum for all the types of work we do in machine learning, including theoretical, foundational and methodological research. I hope you got a sense from part 1 of just how important generative model evaluation is for forecasting, and in part 2 that evaluations are needed at every level of the sociotechical stack. So one evaluation approach you might like to try, and also improve on, is the use of the generalised empirical likelihood or GEL.
The classical empirical likelihood is a method for inference on the mean - so that is a way of doing a statistical test of whether we estimated a mean correctly. The testing problem can be stated simply as: given n independent samples x1 to xn in Rd from an unknown distribution P, check whether the mean of P is equal to a known constant c (which for us will be related to the real data). Real data has an empirical distribution P-hat. And we can model the set of generated samples with a weighted empirical distribution, which constructs the probability by computing a set of weights pi_i, with the condition that the weights are non-zero and sum to 1. We want to minimize divergence, and find the weights that best match the mean condition. The empirical likelihood is then the solution of the convex problem with objective
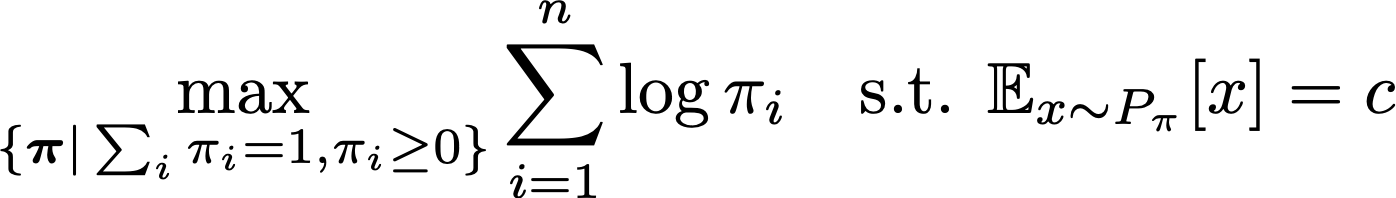
Intuitively, this allows us to check how much does the empirical distribution of the samples have to change to satisfy the moment condition, and this information can be used to understand the deficiencies the generative model might have.
To use this in practice, it's better to generalise it to use a more general moment condition. So you can introduce a more general moment condition m, and constraint Ep(x)[m(x; c)]=0. This change will allow us to match different types of feature vectors or latent representations we might have available from recent advances in representation learning: we can use the pool3 layer features from an inception v3 network (or a layer from another pretrained classifier), use the BYOL features, or use other test statistics that are known from the specific problem. So we get a modified GEL objective.

Because GEL assigns a weight or probability pi to every sample, we can use this weight to individually interrogate samples of the model, and then assess varieties of problems like mode imbalance, mode dropping, effect of guidance scale, or other model design decisions. I won’t show any results for GEL, but the paper has a lot of analyses and experiments. My message here is simply that new evaluations continue to be needed to help us make claims to social-purpose with machine learning; and are now more important than ever.
Fairness Methods
At this point I wanted to use a project in healthcare to further explore the varieties of people-centred design. But my dear friend Marzyeh went into great detail on healthcare problems in her truly excellent talk, so I’ll pass on that; except to say that the intersection of health and environment is yet another area of need, and from which to derive social purpose.
In so many areas of our work with data, a data point represents an actual person - their work, their life, their health, their ideas. Remembering this sets us on a path to expanding the set of considerations for our evaluations, and to always ask where and how people enter into our research and assessments, maybe using the sociotechnical stack as a guide. The most prominent way we do that today is to analyse how models perform across different subgroupings of data, not unlike how we looked at subgroups in environmental prediction problems earlier. For subgroups of people, we often speak about analysing the fairness of our models; and our models can be unfair when context isn’t accounted for and performance across groups of people differs.
In our datasets, people’s legal gender, or self-identified race, or age may be available in the data, which becomes the basis for fairness analysis, and where there is such a rich literature today. But these characteristics won’t always be available. In fact there are many characteristics of people or subcategories of data that may not be available, may be difficult to characterise, or be fundamentally unknowable. This raises the question of what fairness means for these types of unobserved characteristics.
Queer Fairness
Questions like these expose the importance of maintaining our focus on diversity and inclusion in our field. Diverse groups of researchers have the capacity to both use their life experiences in combination with technical expertise to explore solutions for questions like that of unobserved characteristics, and to encourage others to work on them. To connect the dots here, this is just one more way to understand the sociotechnical nature of machine learning and to infuse it with social purpose.
A group of us, using our identities as queer researchers, looked at this question of fairness for unobserved characteristics and the impacts on queer communities specifically. We don’t have have all the answers for difficult questions like this, but we reached one clear conclusion from this work. One reusable methodology available to us right now to understand and evaluate uncertain sociotechnical problems, is to find ways for different types of communities—those who are marginalised, and those who are most vulnerable—to become part of addressing the problem. This is the topic of participation I described earlier. The emphasis of the most vulnerable is important: when we can make our technological tools better for the most vulnerable, we can make them better for everyone.

Indaba
But if everyone is the word we wish to use, this leads to a further question: How do we make AI truly for everyone? How do we make our field really international - like in the name of our conference. Or the way I usually ask this question: how do we make AI truly global?
Answering this question is one I know many of us are thinking about. And we are informed by two theoretical insights.
Firstly, the need to establish meaningful intercultural dialogue as it relates to AI development and research. Intercultural dialogue is core to the field of intercultural digital ethics, and asks questions of how technology can support society and culture, rather than becoming an instrument of cultural oppression and colonialism.
The second insight is the power of strengthening varied forms of political community. As one approach, I am a passionate advocate for the support of grassroots organisations and in their ability to create new forms of understanding, elevate intercultural dialogue, and demonstrate the forms of participation and alternative research community that are already possible.

I’d like to share my own experience of putting this theory of community into practice as I draw to a close. Seven years ago now, I was part of creating a new organisation that we called the Deep Learning Indaba, with a mission to strengthen machine learning across our African continent.
Over the years of our work, we have been able to build new communities, create leadership, and recognise excellence in the research, development and use of machine learning across Africa.
And what a privilege it has been to see new enthusiastic entrants to our field develop their ideas, to receive recognition for their work, to grow and reach enviable successes and new heights, and to know amongst their peers that their questions and approaches are important and part of the way they are uniquely shaping our continent’s future.
And I am so amazed to see so many other groups across the world following in the same vein:
[Khipu Latin American Ai community, eastern european machine learning, south east asia ML, black in AI, queer in AI, latinx in AI, women in ML, ML collective, Data Science Africa, North Africans in ML, Serbian ML researchers, Masakhane NLP, Sisonke Biotik, Lelapa.AI, and so, so many others that I’m forgetting to mention.]
all taking responsibility for their communities and building collectives and movements to support AI, dialogue and transformation.
If we now look back over this last decade, I believe we can honestly say that our field is now more global, and becoming more so, because of the commitment and sacrifices of these groups. Your continued volunteering, funding, support, and openness to these groups shows yet another way of infusing machine learning with social purpose.
Summary
I know that was a lot, but these are topics that are deeply connected to each other. So, if I achieved my aims, then you got to this point with three key outcomes:

- Your Social purpose. Motivate your research using the drive for social purpose. I focussed on machine learning for Earth systems, which is a technically challenging area, one where generative models are proven as a useful approach, and a field that touches upon the entire sociotechnical stack. But whatever we work on, it is the expanded view of what is within our responsibilities that infuses our work with social purpose.
- Reclaim your agency. Develop your view of the ecosystem and the sociotechnical stack, intervene where you best can, and support richer participation in AI development. Nothing in our field is inevitable, and your social purpose has the power to reshape the trajectory of future developments.
- Globalize AI. Our support for grassroots transformation is working, and the expansive thinking on fairness and data quality and where people are represented in machine learning is now almost a part of our everyday practice. We can still do more.
I am deeply grateful for the opportunity to be on this stage, to have the gift of your time, and to have been able in this way to publicly hope for more machine learning with social purpose. My deep, deep thanks to you all.
Postscript
As a short postscript, here are some resources to followup on.

Three books that touch on topics I explored:
- The book by Wallace and Hobbs, Atmospheric Science: An Introductory Survey.
- The Partnership on AI initiative with practices for assessing the impact of AI systems on inequality, and prosperity-outcomes, the Guidelines for AI and Shared Prosperity.
- And a deeply forensic book with clear guidance on changes for stronger equity and inclusion: Equity for women in science: dismantling systemic barriers to advancement.
And pointers to some work I have been able to be a part of with so many amazing collaborators over the years.
- Our paper on predicting and evaluating rainfall forecasts, Skillful precipitation nowcasting using deep generative models of radar.
- Work on 10 day weather predictions, GraphCast: Learning skillful medium-range global weather forecasting.
- Work in philosophy and technology and responsibility, Decolonial AI: Decolonial Theory as Sociotechnical Foresight in AI.
- And finally, a paper on participation, Power to the People? Opportunities and Challenges for Participatory AI.
Again, my sincere thanks to you all.