Our ability to rewrite statistical problems in an equivalent but different form, to reparameterise them, is one of the most general-purpose tools we have in mathematical statistics. We used reparameterisation in all the tricks we explored in this series so far: trick 1 re-expressed a log-partition function in terms of copies (replicas) of the marginal probability, trick 2 re-expressed a binary MRF as an undirected model with Gaussian latent variables, and trick 3 re-expressed the computation of the matrix trace using a randomised form. Such reparameterisations allow us to use different tools for computation, give us a new understanding and approach for analysis, and better expose the connections to related research areas.
Today's trick will focus on one subset of reparameterisation methods, ones we shall refer to as random variate reparameterisations: the substitution of a random variable by a deterministic transformation of a simpler random variable. Machine learning is filled to the brim with random variables, so we'll find many applications of today's trick, including problems in Monte Carlo sampling and stochastic optimisation.
{kind=link}
One-liners
To develop the class of random variate reparameterisations, we will first need to develop the tricks that they themselves rely on: the methods by which non-uniform random numbers, or random variates, can be generated. The most popular methods are the one-liners, which give us the simple tools to generate random variates in one line of code, following the classic paper by Luc Devroye of the same title [cite key=devroye1996random].
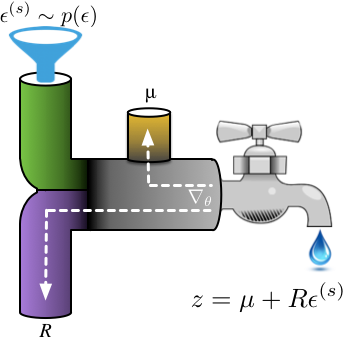
Imagine water flowing through a series of pipes: one-line transformations specify a path  through which samples
through which samples  from an initial base distribution flow, ultimately forming a sample from a desired distribution
from an initial base distribution flow, ultimately forming a sample from a desired distribution  . To be a one-liner, the transformation must be composed of primitive functions (arithmetic operations, log, exp, cos) and the base distribution
. To be a one-liner, the transformation must be composed of primitive functions (arithmetic operations, log, exp, cos) and the base distribution  must be easy to sample from. The transformations, our system of pipes, can be designed in a number of ways. Three popular approaches are:
must be easy to sample from. The transformations, our system of pipes, can be designed in a number of ways. Three popular approaches are:
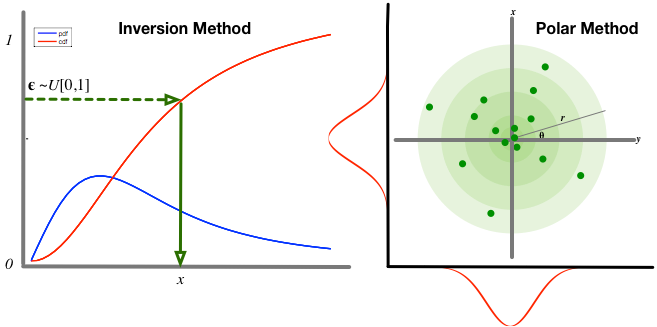
- Inversion methods. To generate a sample from a distribution , we can use the inverse cumulative distribution function (CDF) as our transformation, if it is known and invertible, with uniform random numbers as the base distribution. Many of the distributions we use every day are in this category, so this is a popular default approach.
- Polar methods. Sometimes it is more convenient to think of generating a pair of random variates
 from the target distribution . We can map this pair to a representation in polar form
from the target distribution . We can map this pair to a representation in polar form  , which exposes other mechanisms for sampling, e.g., the famous Box-Muller transform is derived in this way.
, which exposes other mechanisms for sampling, e.g., the famous Box-Muller transform is derived in this way. - Co-ordinate transformation methods. Many co-ordinate transformations exist that allow us to transform one distribution into another form, e.g., using additive or multiplicative location-scale transformations. This will be our default approach since co-ordinate transformations allow for easy reparameterisation of a diverse and flexible class of distributions.
Using this reasoning, you can easily see that the transformations in the table below can be implemented in one line of code; many of the sampling algorithms in our software tools, such as Randomkit used in numpy and torch-distributions, use one-liners. Because generating random numbers is so fundamental, we inevitably have many names for this reasoning, including as non-uniform generators [cite key='devroye1986non'], as simple instances of normalising flows, and as one-liners (and their extended forms).
[table]
Target,
![\[p(z; \theta)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-cd1169ed7f8c077d2cf959ce1f65bcc1_l3.png "Rendered by QuickLaTeX.com")
, Base
![\[p(\epsilon)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-63bf66eff6eaade44e662ba9d30d1dc9_l3.png "Rendered by QuickLaTeX.com")
, One-liner
![\[g(\epsilon; \theta)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-cfc25c538c5099c2b81e1c7232f8cb4e_l3.png "Rendered by QuickLaTeX.com")
Exponential,
![\[\exp(-x); x>0\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-ab6acd9a3e1bd3691f6dc8b6a7712257_l3.png "Rendered by QuickLaTeX.com")
,
![\[\epsilon \sim [0;1]\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-68d978ed95f8fb1587fca01074e1a774_l3.png "Rendered by QuickLaTeX.com")
,
![\[\ln(1/\epsilon)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-4cf54dfce11d0f03aff6c48b9eb9b1b8_l3.png "Rendered by QuickLaTeX.com")
![\[\frac{1}{\pi (1 + x^2)}\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-3f862b1d4ea89ff22b264042125cda3f_l3.png "Rendered by QuickLaTeX.com")
,
![\[\epsilon \sim[0;1]\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-b22852a449320036da258ad8af2e63c1_l3.png "Rendered by QuickLaTeX.com")
,
![\[\tan(\pi\epsilon)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-ad3a40f818b4538e0deefbb82355fb9e_l3.png "Rendered by QuickLaTeX.com")
![\[\mathcal{L}(0;1)=\exp(- |x|)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-75075e5264d7c57d77ea218b3e707bf0_l3.png "Rendered by QuickLaTeX.com")
,
,
![\[\ln(\frac{\epsilon_1}{\epsilon_2})\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-d2883eee9ddc06c2af405edf688412b9_l3.png "Rendered by QuickLaTeX.com")
Laplace,
![\[\mathcal{L}(\mu; b)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-a35b69a0b17064fbc3dca011b246ebe5_l3.png "Rendered by QuickLaTeX.com")
,
,
![\[\mu - b sgn(\epsilon) \ln(1 -2 |\epsilon|)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-dc3ab3d8b6d8bcfae27c3d9d959e3413_l3.png "Rendered by QuickLaTeX.com")
Std Gaussian,
![\[\mathcal{N}(0;1)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-8e50e0b9d57a844069ccbb8de74c4a6c_l3.png "Rendered by QuickLaTeX.com")
,
,
![\[\sqrt{\ln(\frac{1}{\epsilon_1})} \cos(2 \pi\epsilon_2)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-2f4e65667103b3c4375405760c247b4f_l3.png "Rendered by QuickLaTeX.com")
Gaussian,
![\[\mathcal{N}(\mu; RR^\top)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-d0bb22771517ed19b4a8ed16cdee0ffa_l3.png "Rendered by QuickLaTeX.com")
,
![\[\epsilon \sim \mathcal{N}(0;1)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-b68e97b10e9839f383a4ec2dca5a4364_l3.png "Rendered by QuickLaTeX.com")
,
![\[\mu + R\epsilon\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-3549cbe9f6aa2f4aad2b9d2350acd9c8_l3.png "Rendered by QuickLaTeX.com")
![\[Rad(\frac{1}{2})\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-0676f9c40b0b30a0500cbd6f53a8ce2c_l3.png "Rendered by QuickLaTeX.com")
,
![\[\epsilon \sim Bern(\frac{1}{2})\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-84cc358117ffbeb6df967e248e467b29_l3.png "Rendered by QuickLaTeX.com")
,
![\[2\epsilon -1\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-4d5a35ff631dbe06873d42afabfc1380_l3.png "Rendered by QuickLaTeX.com")
Log-Normal,
![\[\ln \mathcal{N}(\mu; \sigma)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-b3129144464bc3dbe709528266a2bd4c_l3.png "Rendered by QuickLaTeX.com")
,
![\[\epsilon \sim \mathcal{N}(\mu;\sigma^2)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-562f9f87c41531659a398c47e2d8a956_l3.png "Rendered by QuickLaTeX.com")
,
![\[\exp(\epsilon)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-24d031c954eb6eac9a40ee92f2182325_l3.png "Rendered by QuickLaTeX.com")
Inv Gamma,
![\[\mathcal{iG}(k; \theta)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-187c625a3f2aca6755506d10d7a0f05e_l3.png "Rendered by QuickLaTeX.com")
,
![\[\epsilon \sim \mathcal{G}(k; \theta^{-1})\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-7c73ddfc07e8fae0dc8c9e4f46d2da38_l3.png "Rendered by QuickLaTeX.com")
,
![\[\frac{1}{\epsilon}\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-5e92ea2560cf166158e380c155fe9d3d_l3.png "Rendered by QuickLaTeX.com")
[/table]
The point of describing these one-liners is that when we see a random variable z, we can often explore the implications of using random variate reparameterisation by replacing z with the function . In Monte Carlo sampling, this approach is sometimes known as a non-centred parameterisation [cite key=papaspiliopoulos2007general], which can lead to more efficient mixing of the Markov chain. Another important application of random variate reparameterisation is in stochastic optimisation, which we explore next.
Reparameterisation for Stochastic Optimisation
One oft-encountered problem is computing the gradient of an expectation of a smooth function f:
![\[\nabla_\theta \mathbb{E}_{p(z;\theta)}[f(z)] =\nabla_\theta \int p(z; \theta)f(z) dz\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-5a4a2ab3b8e9bd0c7efa465eae9a2628_l3.png "Rendered by QuickLaTeX.com")
This is a recurring task in machine learning, needed for posterior computation in variational inference, value function and policy learning in reinforcement learning, derivative pricing in computational finance, and inventory control in operations research, amongst many others. This gradient is often difficult to compute because the integral is typically unknown and the parameters  , with respect to which we are computing the gradient, are of the distribution
, with respect to which we are computing the gradient, are of the distribution  . But where a random variable z appears we can try our random variable reparameterisation trick, which in this case allows us to compute the gradient in a more amenable way:
. But where a random variable z appears we can try our random variable reparameterisation trick, which in this case allows us to compute the gradient in a more amenable way:
![\[\nabla_\theta \mathbb{E}_{p(z;\theta)}[f(z)] = \mathbb{E}_{p(\epsilon)}[\nabla_\theta f(g(\epsilon, \theta))]\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-66dab700d6101b06c874075b37e3e375_l3.png "Rendered by QuickLaTeX.com")
Let's derive this expression and explore the implications of it for our optimisation problem. One-liners give us a transformation from a distribution to another , thus the differential area (mass of the distribution) is invariant under the change of variables. This property implies that:
![\[p(z) = \left|\frac{d\epsilon}{dz} \right|p(\epsilon) \implies | p(z) dz | = |p(\epsilon) d\epsilon|\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-e8024c0b9fe2ba520e1709d7b9298207_l3.png "Rendered by QuickLaTeX.com")
Re-expressing the troublesome stochastic optimisation problem using random variate reparameterisation, we find:
![\[\nabla_\theta \mathbb{E}_{p(z;\theta)}[f(z)] = \nabla_\theta \int p(z; \theta)f(z) dz\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-e3233c5fd7eb9dbaf2230ee6574b3b42_l3.png "Rendered by QuickLaTeX.com")
![\[ =\nabla_\theta \int p(\epsilon)f(z) d\epsilon = \nabla_\theta\int p(\epsilon)f(g(\epsilon, \theta)) d\epsilon\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-dfcbc5cac0dd35b2376ca6da2649986d_l3.png "Rendered by QuickLaTeX.com")
![\[ =\nabla_\theta \mathbb{E}_{p(\epsilon)}[f(g(\epsilon, \theta))] =\mathbb{E}_{p(\epsilon)}[\nabla_\theta f(g(\epsilon, \theta))]\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-daf9e54bdab29001b586b25e98a5731b_l3.png "Rendered by QuickLaTeX.com")
In the second line, we reparameterised our random variable in terms of a one-line generating mechanism. In the final line, the gradient is now unrelated to the distribution with which we take the expectation, so easily passes through the integral. Our assumptions throughout this process were simple: 1) the use of a continuous random variable z with a known one-line reparameterisation, 2) the ability to easily generate samples
![\[\epsilon\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-d7b18f78571c458e567622238f3c07ae_l3.png "Rendered by QuickLaTeX.com")
from the base distribution, and 3) a differentiable function f.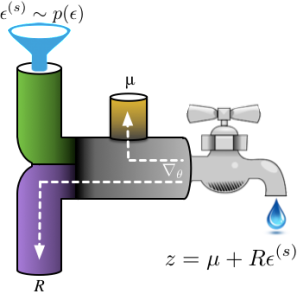
Using reparameterisation has given us a new approach for optimisation: we can obtain an unbiased estimator of the gradient by computing the expectation by Monte Carlo integration. Using the water-pipes analogy, once samples of are available, they flow through the path specified by the transformation to produce random variates. Gradients flow backwards through this path, allowing for computation by automatic differentiation and composition with other gradient-based systems.
![\[ \mathbb{E}_{p(\epsilon)}[\nabla_\theta f(g(\epsilon, \theta))] = \frac{1}{S}\sum_{s=1}^{S}\nabla_\theta f(g(\epsilon^{(s)}, \theta)), \quad \epsilon^{(s)}\sim p(\epsilon)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-160a1490c84bc85ae8cbf813b8818ba1_l3.png "Rendered by QuickLaTeX.com")
As with the one-liners, this approach appears under many different names:
- Perturbation analysis and pathwise derivatives. In stochastic optimisation, the reparameterised gradient estimator appears under the heading of perturbation analysis [cite key= fu2006gradient]. Much of the initial work used a reparamaterisation using one-liners based on the inversion method. The resulting estimators are sometimes called pathwise derivative (PD) estimators [cite key=glasserman2003monte]. The works by Fu, and Glasserman are comprehensive references using this perspective.
- Stochastic Gradient Estimation, M. Fu.
- Gradient estimation via Perturbation analysis, P. Glasserman, Springer, 1991.
- Stochastic backpropagation. There are a number of recent uses of random variate reparameterisation in machine learning to develop scalable variational inference in deep generative models and Gaussian processes. At least three papers concurrently explored this approach:
- Stochastic Backpropagation and Approximate Inference in Deep Generative Models
- Random variate reparameterisation is one consequence of the technique described as stochastic backpropagation in this paper [cite key=rezende2014stochastic]. There also are other ways to derive unbiased gradient estimators and this paper discusses this aspect and provides some simple variance analysis.
- Auto-Encoding Variational Bayes
- We can attribute the popularity of the expression 'reparameterisation trick' to this paper [cite key=kingma2014auto], which provides a clear description of the trick and the range of transformations available.
- Doubly Stochastic Variational Bayes for non-Conjugate Inference
- Stochastic Backpropagation and Approximate Inference in Deep Generative Models
- Affine-independent inference.
Since we obtain a Monte Carlo estimator, there are now important questions to ask about the variance of the estimator. Being pathwise gradients (i.e. they implement the chain-rule), these estimators provide an implicit tracking of dependencies between parameters—a provenance tracking—which contributes to the low variance. Gradient estimators based on this approach often have the lowest variance amongst competing approaches. We can also think about ways in which reparameterisation might allow for efficient computation of higher-order gradients. This stochastic optimisation problem can be solved in another very different way and our next trick, the log-derivative trick, will continue this theme and explore these aspects further.
Summary
Random variate reparameterisation is a tool by which we substitute random variables of some known distribution by a deterministic transformation of another random variable. One of the underlying tools that provide us with the deterministic transformations that are needed to achieve this, are the one-liners. Armed with these tricks, we can develop alternative approaches to often-encountered machine learning problems, resulting in faster mixing Markov chains, or scalable Monte Carlo gradient estimators. These methods remain simple and easy to implement, and is what cements their popularity as a tool for developing accurate and scalable machine learning systems.
[bibsource file=http://www.shakirm.com/blog-bib/trickOfTheDay/oneliners.bib]
Awesome post! Quick note: the one-liner for a standard Gaussian should be sqrt(2 * ln(1/eps_1) * cos(2 * pi * eps_2)
see : https://en.wikipedia.org/wiki/Box%E2%80%93Muller_transform
Fabulous introduction on the reparametrization tricks! Will keep learning from you blog and presumably will get tremendous abundance of knowledge. Just a little confusing about the variable transformation part, according to the introduction on the Wiki link you posted, the implication arrow between p(ϵ)|dϵ|=p(z)|dz| and p(z)=∣dϵ/dz∣p(ϵ) the other term should be perhaps the other way around. Please correct me if i've made mistakes, but following from the measure theory the measure of dz, i.e. p(z), should be 'preserved' under the inverse mapping f^-1: z->ϵ, so that p(ϵ)|dϵ|=p(z)|dz|, then the LHS equation can be implied. Thank you again for your posting and wish i may contribute to the work a little, too.
Thanks a bunch! One question: is the reparametrization trick restricted to transformations where the Jacobian is diagonal? I'm just asking because you took |d eps / dz | apart as if it was.
GREAT article, thanks!
Hi!
Very nice article, it makes for a nice read and explains some basic concepts. I have a question though. Somewhere you say that the vanilla gradient is hard to compute because
"This gradient is often difficult to compute because the integral is typically unknown and the parameters θ, with respect to which we are computing the gradient, are of the distribution p(z;θ)p(z;θ)."
I recognize the first difficulty. Indeed, if your function f() is complicated, like a neural network, computing analytically the integral is hard.
However, what do you mean exactly by the second difficulty? Do you mean that because the variable θ with respect to which you take the gradient is also in the pdf, makes the gradient computation much harder, because the overall composite function becomes harder?
Or because now you need to take the expectation over a multi-dimensional random variable, whereas after the reparameterization trick the expectation is taken over the single dimensional ε? Which implies that you need much fewer samples to compute a good enough expectation, which in turn implies that you can much less variance (or smaller bias) of the estimator?
Thanks Shakir for great posts, please keep doing this.