
An Invited Talk for NACCL-HLT 2021, 8 June 2021. I am extremely grateful to the organisers for the invitation, and a special thanks to Prof. Luke Zettlemoyer who hosted the Q&A session that was so much fun. This is the text of the talk and also has links to the video.

Hello, Hello, Hello. I hope you are enjoying the virtual conference and I’m so excited to get to be here with you all today. Congratulations on hosting this vitally important community meeting this year. And my deep thanks to the organisers for giving me this platform to speak to you all today.
It is now June 2021. Before I start I would like to dedicate my talk today to Dr Sindiswe Van Zyl, an inspirational doctor, feminist, activist, community leader, and fellow South African, who died of COVID19 in April this year. Please join me in a short moment of silence and remembrance, not just for Sindi, but for all those people we lost during this ongoing pandemic. The inequalities that this pandemic exposed will be relevant to our conversation today, as well as this theme of silence and memory. And you’ll hear a bit more from Sindi later.

A little bit about me as I begin. My name is Shakir Mohamed, and I use the pronouns he or they. I’m today more of a wandering intellectual than anything else: I continue to think about the problems of modelling and inference in probabilistic models, but find myself ranging further away, into situated domains in healthcare and environment, and beyond that into the social and ethical questions this research attempt raises. Not being a card carrying member of the computational linguistics and natural language processing community, I was nervous, and also uncertain about what to talk to you about. But I quickly reminded myself of how much we all, across the computational sciences, have in common, so I gathered my confidence and thought we could explore a set of seemingly disparate, yet deeply connected topics that are often on my mind .
I was once at a meeting where someone described themself to me as “being in the business of creating new realities”. I thought to myself, this is a Kween and just how awesome that was as a one line self-description. I’ve been struck by that description ever since, and have often wondered about the ways that we might all be able to describe ourselves, and importantly, our work, using those same words.
So that’s what I thought we might have a conversation about today: Generating Reality: Technical and Social Explorations in Generative Machine Learning Research.
Of course to even have a conversation about Generating Reality, we’ll have to explore what we might mean by this expression generative machine learning. So if you have the chat function or if we meet later, please share your response to this initial question. What does generative machine learning mean to you? What is your gut reaction? Do you think this is a useful term for any form of discourse in machine learning? What do you like or dislike about it? Basically, any thought you have about this question: what is generative machine learning?
My aim is to play with this word generative today. It can mean many things, but I’ll mainly use it in two ways. There is a technical version. And there is a sociotechnical version. Using both ways, I am going to encourage you to incorporate a generative approach into your research. So the rest of my talk is structured in 3 parts.
PART I: Model, Inference, Algorithm
To delve deeper into this topic of generative machine learning, it will be particularly useful to have a structural view of the topic: to understand the technical structures and the components that come together into whatever we call generative machine learning. Also, not anything in machine learning can claim to be generative, because we as a community give meaning to any definition, and accept some and reject others. I like to think of this as a Poetics of machine learning: this combination of technical structures and interpretive communities that we use to understand our field. Within this poetics lives many different representations of our field, and I want to pick up on one today.

To be generative means to imagine, sample, simulate, create, confabulate, synthesise, mimic, or fake: to generate parts of the world we represent as data. We can ask to generate data of the forms we have observed or measured, or generate realities that might not have been but might reasonably occur. So given this description, generative machine learning is naturally studied using the language of probability.
At its core, generative learning relies on the use of systems of consistent and plausible reasoning, statistically accumulating data and evidence, and using it as the natural generalisation of logic for a world with uncertainty. Using the language of probability we can then unpack generative machine learning within a framework that is a triple of models, inference and algorithms. In this view, our work in machine learning is best thought of as composed of two key parts: a model that is a description of the world and data we are studying, and a set of inferential methods that allow probabilistic and plausible reasoning in that model. Since we have many models and inferential methods, any specific choice of model and inference are then combined into a specific algorithm.
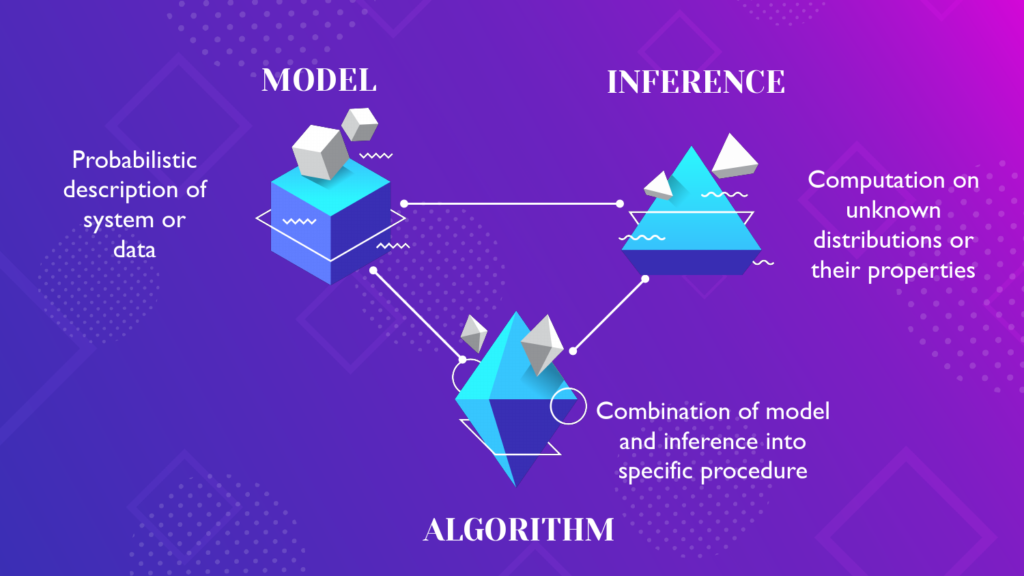
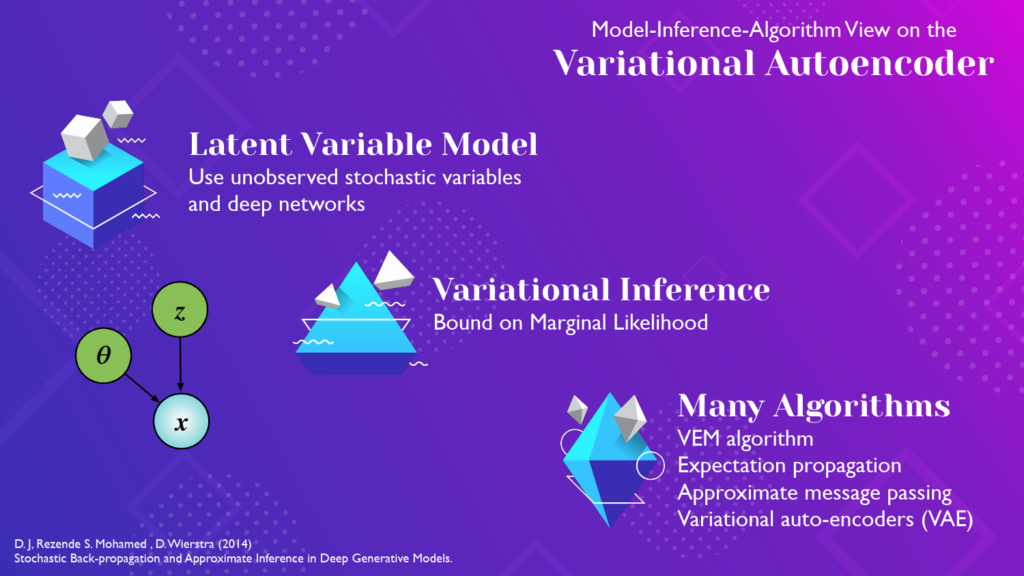
Let’s make this concrete to think about the popular variational autoencoder or VAE. It is common to hear and read an incorrect expression of “a VAE model”. Probably what i’m disagreeing with is the use of the word model here. For me, the VAE is an Algorithm with specific choices for optimisation and efficiency that arises through the combination of a latent variable model, and using an inferential procedure based on variational inference.
Models are the first part of this model-inference-algorithm triple.
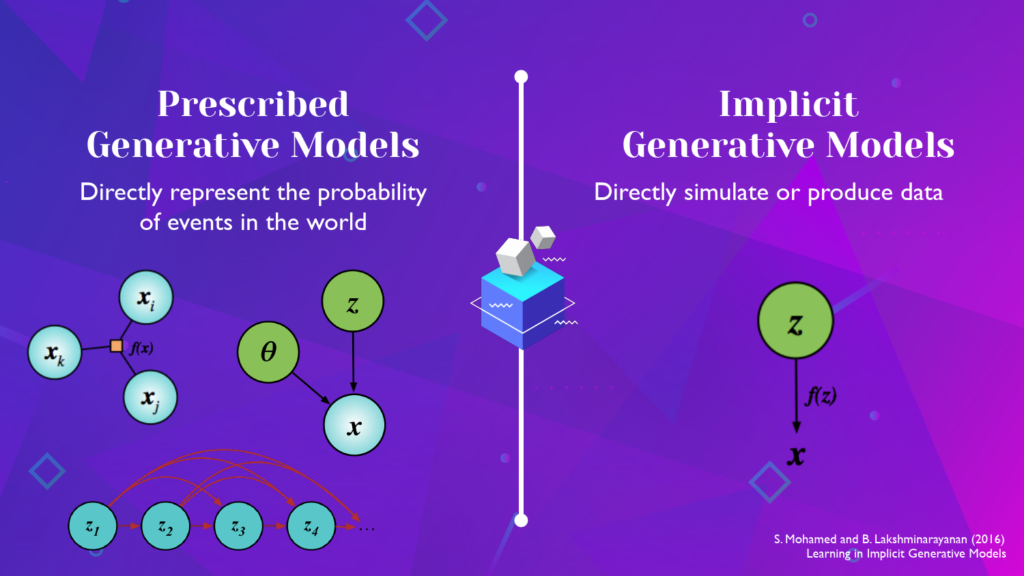
What kinds of statistical models are available to use for generative learning? One helpful distinction is between prescribed and implicit generative models.
- Prescribed models are those models that make use of likelihood functions and aim to directly represent the probability of events in the world. Most models we come across in books in machine learning and statistics are of this form, whether they are the foundational generative models like PCA and factor analysis, state space models like that used in HMMs or the Kalman filter, or more recent deep generative models.
- Implicit generative models are data simulators. They describe a likelihood implicitly not directly. Many models are of this form including simulators of physical systems, samplers of phylogenetic trees, neural samplers, and graphics engines.
The type of model we are interested in is important in establishing what can and cannot be done with such models. Importantly, the choice of one type of model over another makes different types of inferential methods possible.
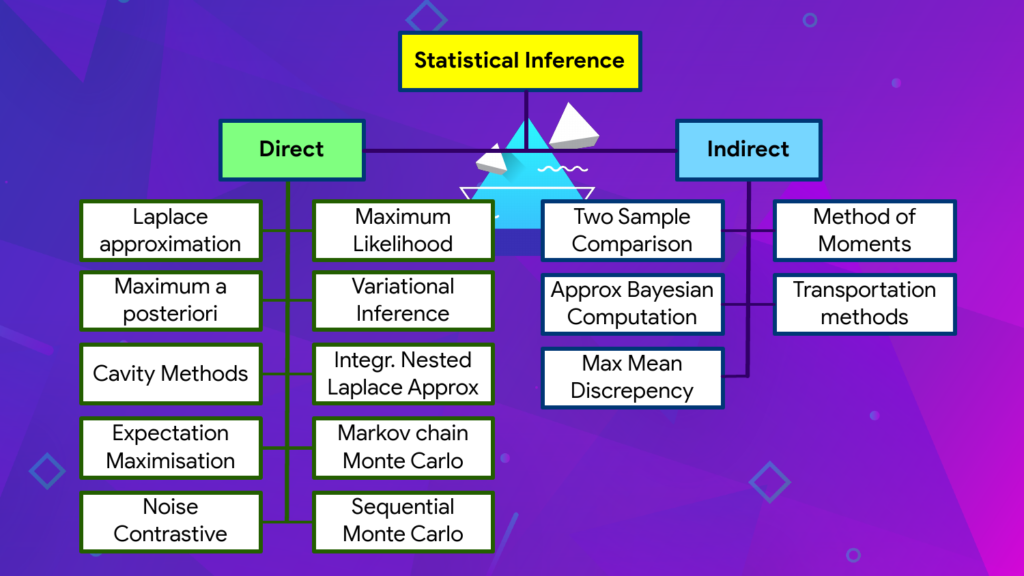
I find it equally useful to break approaches to inference into two different types, thinking of direct and indirect inferential methods. Just to be clear, inference is not the forward evaluation of a trained model. In probabilistic models, inference is the computation and evaluation of unknown probability distributions.
- Direct inferential methods turn all computation to the task of estimating or simply knowing of the data probability p(x). This could also be a bound or approximation of the data probability. All the familiar methods like maximum likelihood or variational inference or Markov chain Monte Carlo are direct inferences.
- Indirect inferences instead take the view that directly targeting the data probability is simply too hard. Instead we can learn by tracking how the data probability changes by looking at how it behaves relative to something else. Other methods like approximation Bayesian computation or the method of moments, or adversarial and density ratio methods fall into this category.
It is the problems of inference that I’ve had the most fun in my explorations of generative machine learning. I’d like to review two topics in probabilistic inference that arise through our study of generative models. when you try to describe them, they all somehow become more basic questions of how to manipulate probability distributions.
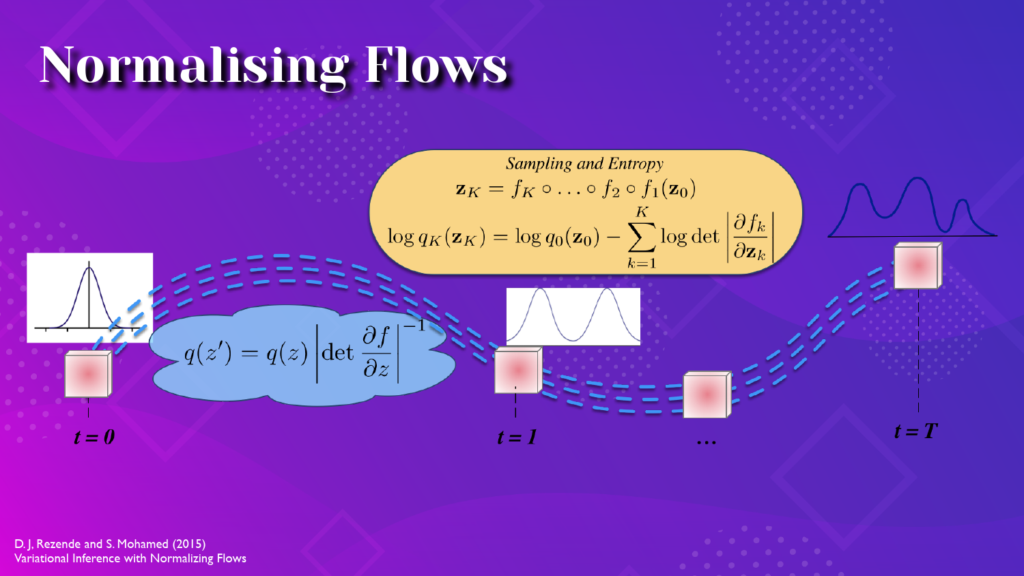
The first of these topics is how to represent a distribution. Distributions can be represented analytically if they are simple enough, or through a collection of samples, or through a sampling program. For the kinds of complex data we find today, relying on simple analytic forms is too weak a methodology. And relying on samples alone places a possibly heavy memory and computational burden in addition to being computationally clunky. Normalising Flow tries to fill the middle ground, by instead starting with a known and simple distribution and then modifying it using repeated operations to represent more complex distributions,; relying on the rules for change of variables in probability. If we can do this, then any distribution can be represented as long as we know how to sample the base distribution and know the program that modifies those samples. This process allows both easy sampling and entropy evaluation. Today there are complex normalising flows for almost any type of data we can imagine. But I don’t think we have exhausted the important questions of how to represent distributions: there are still important questions of efficient computation, handling high-dimensionality, discrete data representations, new flows for specific applied problems, the important role of probabilistic programming, and theory related to efficiency and performance.
A second topic looks at how to represent the gradient of a distribution. This problem appears in both variational inference and adversarial learning, but is also one of the oldest statistical problems. This problem, known as sensitivity analysis, asks how we compute the gradient of an expectation of a function, when we want the gradient with respect to the parameters of the measure. We don’t know this integral in closed form, it might be high-dimensional and hence difficult to compute, and we might only know partial information about this system. Also, first computing the integral and then taking the gradient seems wasteful somehow. Just looking at this problem as an equation, there are some clear objects of importance: the gradient, the measure and the cost. so to compute the gradient, there seem to be only two things to do, you can either manipulate the measure, or manipulate the cost.
By manipulating these probabilities like we did previously, we’ll be able to come up with at least three ways of doing this, giving rise to three families of estimators for the gradient, known as the score function estimator, the pathwise derivative estimator, and the weak-derivative estimator. This is a seemingly anodyne problem, but appears everywhere you look: in logistics and queues, in algorithmic gaming systems, and is with as we enter new periods of scientific advancement. And again, much more work remains in expanding this thinking: to new continuous-time systems, mixing these estimation methods, developing deeper theories of estimator variance, and understanding how choices of smoothness and other properties of our model affect performance.

I also wanted to talk about the role of memory systems and amortised inference in sharing statistical strength within inference methods, and also the forgotten role of hypothesis testing as a basis of inference through comparison. But I’ll leave these topics for another day. And like in any area, the role of evaluation remains crucial and where we must continue to deepen our study, and for which we still lack the broad set of tools that are increasingly needed.
Now, If generative modelling were to remain purely a field of methodology and theory then that would be a sad outcome. Fortunately, today generative modelling is not a purely statistical field, it is also an engineering field. And I think I don’t need to say too much about all the many areas in which generative models have found applications, ranging from digital technologies for large-scale image recognition, natural language generation, and image-to-text and text-to-image translation, as well as in scientific domains from galactic exploration to protein understanding. And in a convenient cycle of reinforcing knowledge, our engineering efforts lead to new statistical questions, and those statistical questions in turn allow us to build more robust systems, and so the wheel turns.
One domain I’m especially committed to, is the role of machine learning to support our urgent response to environmental change as a result of the climate crisis. One tool of increasing need, is the ability to make predictions of environmental variables. The problem of nowcasting, in which we make very short-term predictions of environmental variables like rain, is one area where we’ve shown the clear advantage of using generative models. Generative approaches can produce significantly more accurate predictions compared to the current state of the art, and can provide genuine decision-making value to experts.

More generally, generative approaches are a natural candidate for developing digital twins: digital simulations of the physical infrastructure like buildings, roads, train systems, and energy networks. Investment in digital twins will increase dramatically over the next decade as one part of our climate response and net-zero attainment strategy. These approaches are very much part of ongoing policy discourse for which we as technical designers can also contribute.

As I close this first part, I want to emphasise the core philosophy that lies at the heart of generative machine learning. The principle, always at play, is that there is an underlying data generating process that we are trying to discover and emulate. Our task, using the language of probability, is to capture the living reality that generates the experiences and opportunities and actions that we record as data and use to build our models. To make our models useful, we also acknowledge that we simplify and abstract away many parts of that real, underlying or true generative process. A deep commitment to generative thinking is then to ask ever-deeper questions about data generating processes. This type of deep generative commitment i believe, naturally encourages us to ask questions that extend beyond the immediate technical scope of problems of the types I discussed. This commitment allows us to see that our data comes not only from technical domains and questions and processes, but also from a broader social world. We understand that the social world is an inherent part of any generative process, and part of our attention must go towards understanding that broader reality. So on to the next part.
PART II: Critical Practice
Because we recognise that generative processes are derived from and embedded within a social reality, they should be understood not as purely technical systems, but instead as sociotechnical systems: models and algorithms and processes are influenced by the social world, and in turn themselves influence that social world. The expression often used to describe this is to say that “technology and society are mutually constitutive”. Of course, I don’t believe this is news to anyone here, since researchers like you in NLP and language technologies have always understood the position of language and their work in relation to society and culture.
Many applications of generative models appear under the more general heading of synthetic media, covering everything from the seemingly benign to the dystopian. We can all come up with examples of face swap apps or art generators or speech and language generators in this category. As a field I believe we now accepts that we can’t continue to motivate for the benefits of our research and work, without also contending that our work can cause or be implicated in harm. To talk about benefits without talking about risks is to be naive in our understanding of the place of our research. To talk about risks without contending with whether those risks are shared uniformly is to repeat that mistake.
The harms that have been documented as a consequence of AI applications across the world—whether in facial recognition, predictive policing, misinformation, resource distribution, shifts in labor practice, or health care diagnostics—did not emerge by chance. They result from long-term, systematic mistreatment and inadequate legal and economic protections. Any desire to use our research to support a more prosperous society will have to contend with this legacy, and in particular with at least three distinct forms of algorithmic harm: algorithmic oppression, algorithmic exploitation, and algorithmic dispossession.

Algorithmic oppression describes the unjust privileging of one social group at the expense of others, maintained through automated, data-driven, and predictive systems. From facial recognition to predictive policing, such systems are often based on unrepresentative datasets and reflect historical social injustices in the data used to develop them. amidst the COVID-19 pandemic, unrepresentative datasets have meant biased resource allocation, and prediction models further exacerbated health inequalities already disproportionately borne by underserved populations. Much of the current discussion about “algorithmic bias” centres on this first category of harm.
Algorithmic oppression manifests during the deployment and production phase of AI. Algorithmic exploitation and dispossession emerge during the research and design phase. Exploitation is perhaps clearest within the realm of workers’ rights, where large volumes of data required to train AI systems require annotation by human experts—the so-called “ghost workers”. These jobs are increasingly outsourced to regions with limited labour laws and workers’ rights, rendering them invisible to researchers and fields of study that rely on them. Algorithmic exploitation construes people as automated machines, obscuring their rights, protections, and access to recourse—erasing the respect due to all people.
Algorithmic dispossession is, at its core, the centralization of power, assets, and rights in the hands of a minority. In the algorithmic context, this can manifest in technologies that curtail or prevent certain forms of expression, communication, and identity (such as content moderation that flag queer slang as toxic) or through institutions that shape regulatory policy. Similar dispossession dynamics exist in climate policy, which has been largely shaped by the environmental agendas of the Global North—the primary beneficiary of centuries of climate-altering economic policies. The same pattern holds for AI ethics guidance, despite our technology’s global reach.
These three harms are part of the larger exercise in memory and analysis of the social data generating process. What are the attitudes, and knowledge bases and approaches to doing our research that lead us to contributing to such harms in the world? I'll argue that these attitudes are the foundations and remnants of an older way of living and thinking inherited by us all from our shared experience of colonialism. Colonialism was amongst the last and largest missions undertaken with the aim to do ‘good’ - ostensibly to bring civilisation and modernity and democracy and technology to those that did not have it. Colonialism touched every part of our planet. Colonialism’s impacts continues to influence us today:
- physically in the way our borders are shaped,
- psychologically in how we think about ourselves and each other,
- linguistically in the role of English today as the language of science and exchange,
- by racism and racialisation that was invented during the colonial era to establish hierarchical orders of division between people,
- economically in how labour is extracted in one place and profit generated elsewhere,
- and politically within the structures of governance, laws and international relations that still fall along colonialism’s fault lines.
We refer to colonialism’s remnants and impacts on knowledge and understanding in the present using the term coloniality. So part of the exercise i’ll leave for you is to contend with the coloniality of NLP. To list all the ways that we have inherited and reproduce, through technology, a colonial attitude to the world.

Let’s deviate now to explore one last, but related topic. There was an exchange on twitter by Dr Sindi who I remembered in the opening. The scene is a health consultation with a 65 year old patient that unfolds like this. She asks.
Me: Mama are you in a relationship?
Mama: no. My husband died 15 years ago
Me: do you have a "friend"?
Mama: yes I do have a friend
Me: how often do you "visit" your "friend" ?
Mama: mostly month end
Me: do you use condoms? Yes? No? Sometimes
Mama: sometimes
Twitter conversation from Dr Sindi Van Zyl
There is a lot going on in this scene. But what I want us to take from it, is the role of silence in language. One needed to know that elderly women in South Africa don’t have boyfriends or sides, they have friends. Relying on this context, in the silences and in-betweens, this conversation is able to talk about the sexual activity of the patient, without ever directly naming it.
We have a bias for speech over silence. A bias for language over listening. This is a subtle, pervasive, and overpowering form of benevolence and over-confidence in our technical work. Yet, what technical system today, even if trained on all the language data possible, would be able to really make use of cultural difference and context to do what we saw in this short conversation.
The decolonisation of language is a topic with a long history. Much has been done, and much more remains. So how do we create a new field of Decolonial NLP?

PART III: Generative Practice
Part II of our discussion took us into the technical realm of criticism. We covered a lot of concepts: technological harms, algorithmic exploitation, oppression and dispossession, colonialism and coloniality, and the place of cultural context and difference and listening and silence. Let’s now move from being critical to an attempt at being generative: an attempt to find new ways of addressing the concerns and problems we explored. This is the second way of generating reality I promised we’d consider.
One starting place is to examine the fundamental basis upon which we approach our work is built. Many of our implicit biases and unquestioned beliefs about knowledge reveal themselves in the attitudes we sometimes take when doing research and deployment. Let’s look at 5 of these attitudes
- Knowledge transfer. By their nature, the scientific projects we work on implicitly or explicitly acknowledge that knowledge and expertise is imbalanced in the world. To have research benefit humanity, part of our work seemingly becomes to assist the migration of knowledge from centres of power (like our research laboratories) to places where it is lacking.
- Benevolence. An implicit attitude that emerges is that, where information, knowledge, or technology is lacking, technical development should be undertaken by the knowledgeable or powerful on behalf of those others who are to be affected or changed by it.
- Portability. We easily slip into the belief that ideas and techniques applied to any particular place or situation are just as easily applicable to any other situation or place. We believe that knowledge developed anywhere will always work just as well anywhere else, although this is rarely the case.
- Quantification. An inevitable conversation is that quantification and statistical accounts of the world as a tool for comparison, evaluation, understanding, and prediction is the sole way of understanding the world.
- The Standard of Excellence. As a last attitudinal concern, do we assume the standards and forms and the world within our research labs in our countries - so that is, within our centres of knowledge and technical power - are to be models of the future for other regions.
These attitudes appear all across our work. As one example, most current approaches for algorithmic fairness assume that the target characteristics for fairness--frequently, race and legal gender--can be observed or recorded, and with this information are fairness assessments made. Yet most characteristics will instead be unobserved: they will be frequently missing, unknown, or are fundamentally immeasurable. Sexual orientation and gender identity are instances of these immeasurable characteristics.
Queer fairness exposes a form of silence that is worthwhile considering. And navigating this silence is a fundamental component for all of us with queer identities. To know this silence, recall a core tenet of queer life, that we don’t out people - we just don’t do it. Default attitudes of quantification and portability lead us as researchers to reach for the ‘get more data’ solution to many problems, asking about these characteristics through more self-id exercises and surveys; it leads us to go against this form of fundamental element of respect. When these exercises are useful, will, as always, require more detailed thought, analysis, and listening.

Queer life, if we are open to including it, can provide insights into the challenging questions facing our fields. Queer fairness underscores the need for new directions in fairness research that take into account a multiplicity of considerations, from privacy preservation, context sensitivity and process fairness, to an awareness of sociotechnical impacts and the increasingly important role of inclusive and participatory research processes. By bringing the expertise and experience of queer people and communities into our research, by recognising that there is knowledge that we don’t have, and that not all knowledge must be codified in the language of science to be valuable, we can together problematise and unpack these difficult questions.
I’m using this problem of queer fairness to ask a bigger question about how we support new types of political communities that are able to reform systems of hierarchy, knowledge, technology and culture at play in modern life. As one approach, I am a passionate advocate for the support of grassroots organisations and in their ability to create new forms of understanding, elevate intercultural dialogue, and demonstrate the forms of solidarity and alternative community that are already available to us.
I would like to share my own experience of putting this theory of community into practice. Around 5 years ago, I was part of a collective of people to create a new organisation, called the Deep Learning Indaba, whose mission is to strengthen machine learning across our African continent. Over the years of our work, we have been able to build new communities, create leadership, and recognise excellence in the development and use of artificial intelligence across Africa. And what a privilege it has been to see young people across Africa develop their ideas, present them for the first time, to receive recognition for their work, and to know amongst their peers that their questions and approaches are important and part of the way they are uniquely shaping our continent’s future.

And I am proud to see other groups having followed in the same vein, in Eastern Europe, in South-east Asia, in South Asia, and South America - in addition to other inspirational community groups like the wonderful Maskhane NLP group, Data Science Africa, Black in AI and Queer in AI: all taking responsibility for their communities and building grassroots movements to support AI, dialogue and transformation. Looking back over the last 5 years, I believe we can now honestly say that global AI is now more global because of the commitment and energy of these groups.

I suppose I’m not saying much more than that being generative is hard. To generate different realities needs new approaches and thinking that we might not have. But for this reason it will be essential for us to continue to break disciplinary boundaries. The chains that keep us immobile are many: our publishing incentives, research cultures, the conundrum of global ambition with distinctly non-global representation, the pressures of funding, independence, competing interests, recognition, and relevance. Our conferences are one way of shaping research culture. And so to are our choices as a field. So much work lies ahead for us all, but a generative attitude is one tool we all have at our disposal.
If I’ve accomplished some of what I set out to do, then we have reached this point propelled by two key themes.
- Firstly, that the technical world and the social world have always been deeply entangled. We are entangled in it today, right now, wherever it is you might be watching this from. Generative machine learning is a clear embodiment of this entanglement.
- Secondly, to be ahistorical and uncritical in our approach to machine learning risks us falling into default attitudes of coloniality, ignoring the silence and listening needed as part of our new practice.
I’ll end here, leaving my sincere thanks for reaching this point with me. The future is not determined. The safe and trustworthy and generative technology of tomorrow, begins with our effort today. That transformation, I think, lives in the mundane – in our everyday acts of thoughtfulness and joy.
To end, i thought we could read a short poem together. It’s a famous one, but it connects to this idea of generation and imagination, ad it’s opening lines are ones i go back to again and again. This is Wild Geese, by Mary Oliver.

As a short postscript, here are some resources and papers that might be interesting.
As a short postscript, here are some resources and papers that might be interesting. [...] And some of my own papers that I referred to:
- A review paper on the problem of sensitivity analysis: Monte Carlo Gradient estimation in machine learning.
- A paper on foresight and harms. Decolonial AI: Decolonial Theory as Sociotechnical Foresight in AI
- A paper on queer fairness. Fairness for unobserved Characteristics: Insights from Technological Impacts on Queer Communities
- And a 5 min book review called Domesticating the Techno-racial project.

