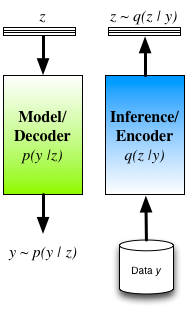
'Tricks' of all sorts are used throughout machine learning, in both research and in production settings. These tricks allow us to address many different types of data analysis problems, being roughly of either an analytical, statistical, algorithmic, or numerical flavour. Today's trick is in the analytical class and comes to us from statistical physics: the popular Replica trick. The replica trick [cite key="engel2001statistical"][cite key="sharp2011effective"][cite key="opper1995statistical"] is used for analytical computation of log-normalising constants (or log-partition functions). More formally, the replica trick provides one of the tools needed for a replica analysis of a probabilistic model — a theoretical analysis of the the properties and expected behaviour of a model. Replica … Continue reading Machine Learning Trick of the Day (1): Replica Trick