Deep learning and the use of deep neural networks [cite key="bishop1995neural"] are now established as a key tool for practical machine learning. Neural networks have an equivalence with many existing statistical and machine learning approaches and I would like to explore one of these views in this post. In particular, I'll look at the view of deep neural networks as recursive generalised linear models (RGLMs). Generalised linear models form one of the cornerstones of probabilistic modelling and are used in almost every field of experimental science, so this connection is an extremely useful one to have in mind. I'll focus here on what are called feedforward neural networks and leave a discussion of the statistical connections to recurrent networks to another post.
Generalised Linear Models
The basic linear regression model is a linear mapping from P-dimensional input features (or covariates) x, to a set of targets (or responses) y, using a set of weights (or regression coefficients) β and a bias (offset) β0 . The outputs can also by multivariate, but I'll assume they are scalar here. The full probabilistic model assumes that the outputs are corrupted by Gaussian noise of unknown variance σ².
![\[\eta = \beta^\top x + \beta_0\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-ae28d4e04788a762cf8b29309fd3c851_l3.png "Rendered by QuickLaTeX.com")
![\[y = \eta+\epsilon \qquad \epsilon \sim \mathcal{N}(0,\sigma^2)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-3dcbeb1234730d309e2fee40ec0107c8_l3.png "Rendered by QuickLaTeX.com")
In this formulation, η is the systematic component of the model and ε is the random component. Generalised linear models (GLMs)[cite key="mccullagh1989generalized"] allow us to extend this formulation to problems where the distribution on the targets is not Gaussian but some other distribution (typically a distribution in the exponential family). In this case, we can write the generalised regression problem, combining the coefficients and bias for more compact notation, as:
![\[\eta = \beta^\top x, \qquad \beta=[\hat \beta, \beta_0], x = [\hat{x}, 1]\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-6fc373c786228a27919ae8b8e32153d6_l3.png "Rendered by QuickLaTeX.com")
![\[ \mathbb{E}[y] = \mu = g^{-1}(\eta)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-5999fa512e9dc3040668e03e278b6188_l3.png "Rendered by QuickLaTeX.com")
where g(·) is the link function that allows us to move from natural parameters η to mean parameters μ. If the inverse link function used in the definition of μ above were the logistic sigmoid, then the mean parameters correspond to the probabilities of y being a 1 or 0 under the Bernoulli distribution.
There are many link functions that allow us to make other distributional assumptions for the target (response) y. In deep learning, the link function is referred to as the activation function and I list in the table below the names for these functions used in the two fields. From this table we can see that many of the popular approaches for specifying neural networks that have counterparts in statistics and related literatures under (sometimes) very different names, such multinomial regression in statistics and softmax classification in deep learning, or rectifier in deep learning and tobit models is statistics.
[table]
Target Type, Regression, Link, Inv link, Activation
Real, Linear, Identity, Identity,""
Binary, Logistic, Logit
![\[ \log\frac{\mu}{1 - \mu}\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-2a63247fcbc320a9f6a9518d1f06ea2b_l3.png "Rendered by QuickLaTeX.com")
, Sigmoid σ
![\[\frac{1}{1 + \exp(-\eta)}\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-08e75483980fed0ae00a96dee2eb17fb_l3.png "Rendered by QuickLaTeX.com")
, Sigmoid
Binary, Probit, Inv Gauss CDF
![\[ \Phi^{-1}(\mu)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-1ed44dca2a8e4927f164e27df7d504d4_l3.png "Rendered by QuickLaTeX.com")
, Gauss CDF
![\[ \Phi(\eta)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-894bbc6df14748c5bf045ebfe68cb511_l3.png "Rendered by QuickLaTeX.com")
, Probit
Binary, Gumbel, Compl. log-log
![\[ log(-log(\mu))\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-c67dde80525116521299758869b3a060_l3.png "Rendered by QuickLaTeX.com")
, Gumbel CDF
![\[ e^{-e^{-x}}\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-3f497de5b50acda12bb5dcb4db4c6d19_l3.png "Rendered by QuickLaTeX.com")
, ""
Binary, Logistic , "" , Hyperbolic Tangent
![\[ \tanh(\eta)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-15e01bb69b05ae35793f083c38ad6280_l3.png "Rendered by QuickLaTeX.com")
, Tanh
Categorical,Multinomial, , Multin. Logit
![\[ \frac{\eta_i}{\sum_j \eta_j}\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-d3a53dca46240db37448a7681ad298ad_l3.png "Rendered by QuickLaTeX.com")
![\[log(\mu)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-d19b4f285233647717fb9210a0bd08a9_l3.png "Rendered by QuickLaTeX.com")
,
![\[ \exp(\nu)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-d95a84a2fca76ce3a67902997936b041_l3.png "Rendered by QuickLaTeX.com")
, ""
Counts,Poisson,
![\[\sqrt(\mu)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-e39d5977bf87b1fe9d24eaa8703cfc7d_l3.png "Rendered by QuickLaTeX.com")
,
![\[ \nu^2\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-6b9b5a173b7be671f4c4247ea4abf324_l3.png "Rendered by QuickLaTeX.com")
, ""
Non-neg., Gamma, Reciprocal
![\[ \frac{1}{\mu}\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-e62994f82f8483aadc1e25d88445c515_l3.png "Rendered by QuickLaTeX.com")
,
![\[\frac{1}{\nu}\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-5791c214961eb0b4488932f93f0d891d_l3.png "Rendered by QuickLaTeX.com")
, ""
Sparse, Tobit, "", max
![\[\max(0;\nu)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-17bbf9d3133ab77ce0ca8e1dcace1cab_l3.png "Rendered by QuickLaTeX.com")
, ReLU
Ordered, Ordinal, , Cum. Logit
![\[\sigma(\phi_k - \eta)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-304017faff057047dfbca3cc507ffb40_l3.png "Rendered by QuickLaTeX.com")
, ""
[/table]
Recursive Generalised Linear Models

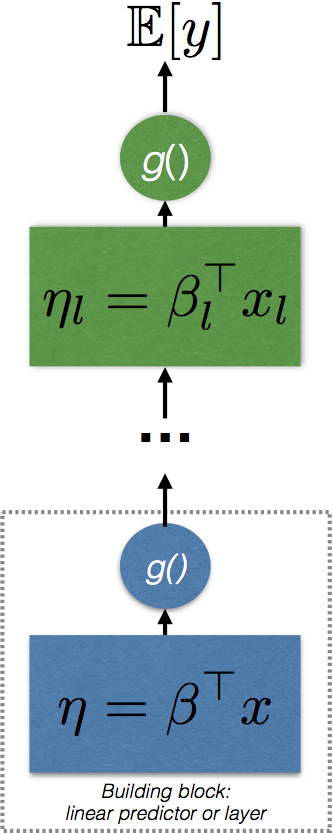
GLMS have a simple form: they use a linear combination of the input using weights β, and pass this result through a simple non-linear function. In deep learning, this basic building block is called a layer. It is easy to see that such a building block can be easily repeated to form more complex, hierarchical and non-linear regression functions. This recursive application of the basic regression building block is why models in deep learning are described as having multiple layers and are described as deep.
If an arbitrary regression function h, for layer l, with linear predictor η, and inverse link or activation function f, is specified as:
![\[ h_l(x) = f_l(\eta_l)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-0c0e7423bea760c67bd7b0674098ed15_l3.png "Rendered by QuickLaTeX.com")
then we can easily specify a recursive GLM by iteratively applying or composing this basic building block:
![\[ \mathbb{E}[y] = \mu_L = h_L \circ \ldots \circ h_1 \circ h_o(x)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-33e3a9da1ae85f86b124a7275d5eb70f_l3.png "Rendered by QuickLaTeX.com")
This composition is exactly the specification of an L-layer deep neural network model. There is no mystery in such a construction (and hence in feedforward neural networks) and the utility of such a model is easy to see, since it allows us to extend the power of our regressors far beyond what is possible using only linear predictors.
This form also shows that recursive GLMs and neural networks are one way of performing basis function regression. What such a formulation adds is a specific mechanism by which to specify the basis functions: by application of recursive linear predictors.
Learning and Estimation
Given the specification of these models, what remains is an approach for training them, i.e. estimation of the regression parameters β for every layer. This is where deep learning has provided a great deal of insight and has shown how such models can be scaled to very high-dimensional inputs and on very large data sets.
A natural approach is to use the negative log-probability as the loss function and maximum likelihood estimation [cite key="bickel2001mathematical"]:
![\[ \mathcal{L} = - \log p(y | \mu_L)\]](http://blog.shakirm.com/wp-content/ql-cache/quicklatex.com-fc5531681427bf6db84bcf4a4a12bcae_l3.png "Rendered by QuickLaTeX.com")
where if using the Gaussian distribution as the likelihood function we obtain the squared loss, or if using the Bernoulli distribution we obtain the cross entropy loss. Estimation or learning in deep neural networks corresponds directly to maximum likelihood estimation in recursive GLMs. We can now solve for the regression parameters by computing gradients w.r.t. the parameters and updating using gradient descent. Deep learning methods now always train such models using stochastic approximation (using stochastic gradient descent), using automated tools for computing the chain rule for derivatives throughout the model (i.e. back-propagation), and perform the computation on powerful distributed systems and GPUs. This allows such a model to be scaled to millions of data points and to very large models with potentially millions of parameters [cite key="botouSDGTricks"].
From the maximum likelihood theory, we know that such estimators can be prone to overfitting and this can be reduced by incorporating model regularisation, either using approaches such as penalised regression and shrinkage, or through Bayesian regression. The importance of regularisation has also been recognised in deep learning and further exchange here could be beneficial.
Summary
Deep feedforward neural networks have a direct correspondence to recursive generalised linear models and basis function regression in statistics -- which is an insight that is useful in demystifying deep networks and an interpretation that does not rely on analogies to sequential processing in the brain. The training procedure is an application of (regularised) maximum likelihood estimation, for which we now have a large set of tools that allow us to apply these models to very large-scale, real-world systems. A statistical perspective on deep learning points to a broad set of knowledge that can be exchanged between the two fields, with the potential for further advances in efficiency and understanding of these regression problems. It is thus one I believe we all benefit from by keeping in mind. There are other viewpoints such as the connection to graphical models, or for recurrent networks, to dynamical systems, which I hope to think through in the future.
[bibsource file=http://www.shakirm.com/blog-bib/RGLMs.bib]
This is a brilliant blog post. I come from a statistics background, so I was really interested to learn about ANNs 1-2 years ago and how they relate to the traditional GLM toolkit. I think you're spot on that ANNs can be viewed, in some sense, as an extension of GLMs with further parameterisation within the (higher) link function. GLMs of course still allow for interaction between dependent variables - but the type of interaction is constrained by the link function - so what ANNs are doing is essentially hacking the link function some more to achieve a better fit.
Thanks for the wonderful post. With apologies for the plug, we have
been working on a related idea called "deep exponential families".
Our paper about them is on the arxiv:
http://arxiv.org/abs/1411.2581."
Why does deep learning work? A perspective from Group Theory.
I have a quick comment: I believe there is an error in stating that the errors for the GLM are normally distributed with mean zero and variance sigma^2. The entire point of GLM is to allow for modelling variables which come from distributions with non-gaussian errors... so it should state that the errors, ei, have E[ei] = 0 and Var(ei) = g(mui), where g(mui) is some function of the mean response.