· Read in 8 minutes ·
Our first encounters with probability are often through a collection of simple games. The games of probability are played with coins, dice, cards, balls and urns, and sticks and strings. Using these games, we built an intuition that allows us to reason and act in ways that account for randomness in the world. But these games are more than just pedagogically powerful—they are also devices we can embed within our statistical algorithms. In this post, we'll explore one of these tools: a stick of length one.
Stick Breaking
I need to probabilistically break a stick that is one unit long. How can I do this? I would need a way to generate a random number between 0 and 1. And once I have this generator, I can generate a random number 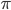 and break the stick at this point. The continuum of points on the unit-stick represents the probability of an event occurring. By breaking the stick in two, I effectively created a probability mass function over two outcomes, with probabilities and
and break the stick at this point. The continuum of points on the unit-stick represents the probability of an event occurring. By breaking the stick in two, I effectively created a probability mass function over two outcomes, with probabilities and 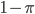 . And I can break these two pieces many more times to obtain a probability mass function over multiple categories, knowing that the sum of all the pieces must be one—the original length of the stick. This gives us an easy way to track how probability can be assigned to a set of discrete outcomes. By controlling how the stick is broken, we can control the types of probability distributions we get. Thus, stick-breaking gives us new ways to think about probability distributions over categories, and hence, of categorical data. Let's splinter sticks in different ways and explore the machine learning of stick-breaking—by developing sampling schemes, likelihood functions and hierarchical models.
. And I can break these two pieces many more times to obtain a probability mass function over multiple categories, knowing that the sum of all the pieces must be one—the original length of the stick. This gives us an easy way to track how probability can be assigned to a set of discrete outcomes. By controlling how the stick is broken, we can control the types of probability distributions we get. Thus, stick-breaking gives us new ways to think about probability distributions over categories, and hence, of categorical data. Let's splinter sticks in different ways and explore the machine learning of stick-breaking—by developing sampling schemes, likelihood functions and hierarchical models.

Stick-breaking Samplers
The beta distribution is one natural source of random numbers with which to probabilistically break a stick into two pieces. A sample 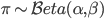 lies in the range (0,1), with parameters
lies in the range (0,1), with parameters  and
and 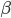 . The essence of stick-breaking is to discover the variable in the range (0,1) hidden within our machine learning problem, and to make it the central character.
. The essence of stick-breaking is to discover the variable in the range (0,1) hidden within our machine learning problem, and to make it the central character.
Enter the Dirichlet distribution. The Dirichlet is a distribution over K-dimensional vectors of real numbers in (o,1) where the K-entries sum to one. This makes it a distribution over probability mass functions, and is described by a K-dimensional vector of parameters 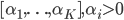 .
.
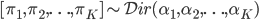
Where is the hidden (0,1)-variable lying in this problem and how can we take advantage of it? The Dirichlet has two very useful properties that addresses these questions.
- The marginal distributions of the Dirichlet are beta distributions.
- Conveniently, the natural tool with which to break a stick is available to us by working with the marginal probabilities. We discover that the Dirichlet distribution is the generalisation of the beta distribution from 2 to K categories.
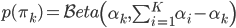
- Conveniently, the natural tool with which to break a stick is available to us by working with the marginal probabilities. We discover that the Dirichlet distribution is the generalisation of the beta distribution from 2 to K categories.
- Conditional distributions are rescaled Dirichlet distributions.
- If we know the probabilities of some of the categories, the probability of the remaining categories is a lower-dimensional Dirichlet distribution. Using
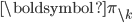 to represent the vector excluding the kth entry, and similarly for
to represent the vector excluding the kth entry, and similarly for 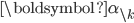 , we have:
, we have: 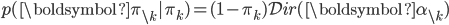
- If we know the probabilities of some of the categories, the probability of the remaining categories is a lower-dimensional Dirichlet distribution. Using
Putting these two properties together, we can develop a stick-breaking method for sampling from the Dirichlet distribution [cite key=sethuraman1994constructive]. Consider sampling from a 4-dimensional Dirichlet distribution. We begin with a stick of length one.
- Break the stick in two. We can do this since the marginal distribution for the first category is a Beta distribution.
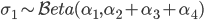
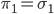
- The conditional probability of the remaining categories is a Dirichlet.
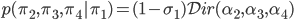
- Break the length of the stick that remains into two. The length of the stick that remains is
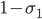 , and using the marginal property again:
, and using the marginal property again: 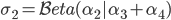
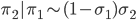
- Repeat steps 2 and 3 for the third category.
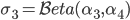
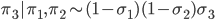
- The remaining length of the stick is the probability of the last category.
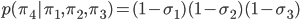
By repeatedly applying the rules for the marginal and conditional distributions of the Dirichlet, we reduced each of the conditional sampling steps to sampling from a beta distribution—this is the stick-breaking approach for sampling from the Dirichlet distribution.
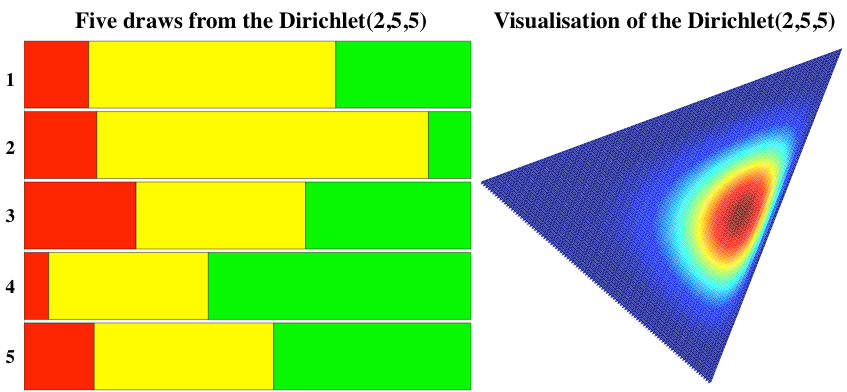
This is a widely-known alternative sampling process for the Dirichlet distribution.
- Theorem 4.2 of Devroye [cite key=devroye2006nonuniform] is one source of discussion, where it is also contrasted against a more efficient way of generating Dirichlet variables using Gamma random numbers.
- Stick-breaking works because samples from the Dirichlet distribution are neutral vectors: we can remove any category easily and renormalise the distribution using the sum of the entries that remain. This is an inherent property of the Dirichlet distribution and has implications for machine learning that uses it, as we shall see next.
Stick-breaking Likelihoods
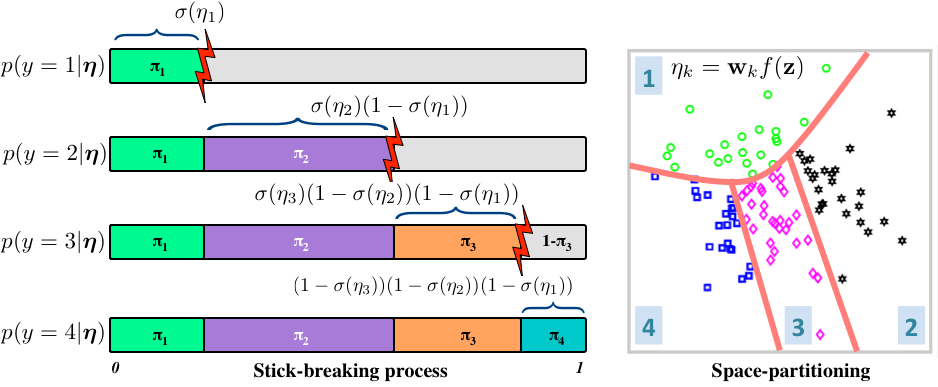
Stick-breaking can be used to specify a likelihood function for ordinal (ordered-categorical) data, and by implication, a loss function for learning with ordinal data. In ordinal regression, we are given covariates or features x, and we learn a discriminative mapping to an ordinal variable y using a function 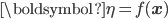 . Instead of using a beta distribution, we will break the stick at points given by squashing the points on the function through a sigmoid (or probit) function
. Instead of using a beta distribution, we will break the stick at points given by squashing the points on the function through a sigmoid (or probit) function 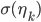 , which is a number in (0,1). If we consider four categories, a stick-breaking likelihood is:
, which is a number in (0,1). If we consider four categories, a stick-breaking likelihood is:
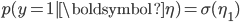
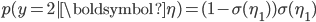
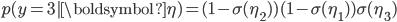
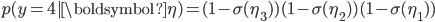
This is exactly the stick-breaking formulation we used for the Dirichlet distribution, but the parameters are modelled as a function of observed data. The function 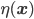 can be any function, e.g., a linear function, deep network or polynomial basis function. The likelihood function carves out the probability space sequentially: each
can be any function, e.g., a linear function, deep network or polynomial basis function. The likelihood function carves out the probability space sequentially: each 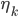 defines a decision boundary that separates the kth category from all categories j>k (see figure).
defines a decision boundary that separates the kth category from all categories j>k (see figure).
We can compactly write the likelihood as:
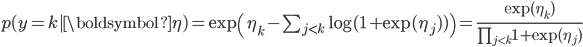
As a log-likelihood, this gives us one type of loss function for maximum likelihood ordinal regression.
- The stick-breaking likelihood has been used for both regression and density estimation problems as an alternative to the more common cumulative logit for ordinal regression.
- The work by Alan Agresti is one of the most comprehensive references for understanding models of categorical data and their assumptions [cite key=agresti1996introduction].
- This stick-breaking is a generalisation of continuation ratio models, commonly used in item response theory, and allows us to further examine the assumptions that follow as a result of the neutrality property. The specific assumption that we should carefully review is independence of irrelevant alternatives (IIA).
Hierarchical Stick-breaking Models
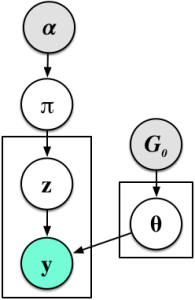
I would like to now consider something far more radical: replacing Dirichlet distributions wherever I find them by stick-breaking representations. Let us experiment with a core model of machine learning—the mixture model. Mixture models with K-components specify the following generative process and graphical model:
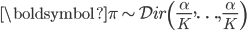
- For c=1, ..., K
- For i=1, ..., n
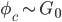
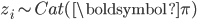
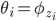
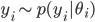
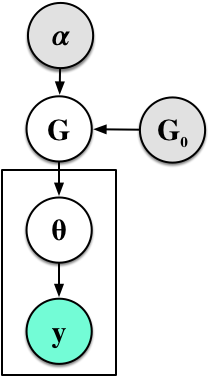
In Gaussian mixtures 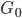 is the distribution of means and variances. When we replace the Dirichlet distribution with a stick-breaking representation we obtain a different, but equivalent, generative process:
is the distribution of means and variances. When we replace the Dirichlet distribution with a stick-breaking representation we obtain a different, but equivalent, generative process:
- For c=1, ..., K
- For i=1, ..., n
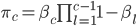

In the first step, we re-expressed the Dirichlet using the stick-breaking, moving it into the loop over the K categories. We then created a discrete mixture G, where sampling from this chooses one of the mixture parameters with probability 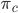 . The final step is then the same as the original. This view is the random measure view of the mixture model.
. The final step is then the same as the original. This view is the random measure view of the mixture model.
We now have an alternative way to express the mixture model that comes with a new set of tools for analysis. We can now be bold enough to ask what happens as the number of clusters 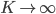 : obviously, we obtain an infinite mixture model. This is one of the most widely-asked questions in contemporary machine learning and takes us into the domain of Bayesian non-parametric statistics [cite key=hjort2010bayesian].
: obviously, we obtain an infinite mixture model. This is one of the most widely-asked questions in contemporary machine learning and takes us into the domain of Bayesian non-parametric statistics [cite key=hjort2010bayesian].
Today Bayesian non-parametric statistics is the largest consumer of stick-breaking methods and uses them to define diverse classes of highly-flexible hierarchical models.
- The stick-breaking representation provides one way to understand the Dirichlet process (DP).
- We repeatedly broke the part of the stick that remained after every sampling step. What if we continue to break the first part of the stick instead? This is what is used in another type of non-parametric model.
Summary
The analogy of breaking a stick is a powerful tool that helps us to reason about how probability can be assigned to a set of discrete categories. And with this tool, we can develop new sampling methods, loss functions for optimisation, and ways to specify highly-flexible models.
Manipulating probabilities remains the basis of every trick we use in machine learning. Machine learning is built on probability, and the foundations of probability endure as a supply of wondrous tricks that we can use every day.
This series has been a rewarding ramble through different parts of machine learning, and will be the last post in this series—at least for now.
[bibsource file=http://www.shakirm.com/blog-bib/trickOfTheDay/stickbreaking.bib]
Nice post. BTW, is there a typo p(y=2|η)=(1−σ(η1))σ(η1), should be η2?
Yes, I agree. In the first set of equations in the section Stick-breaking Likelihoods.