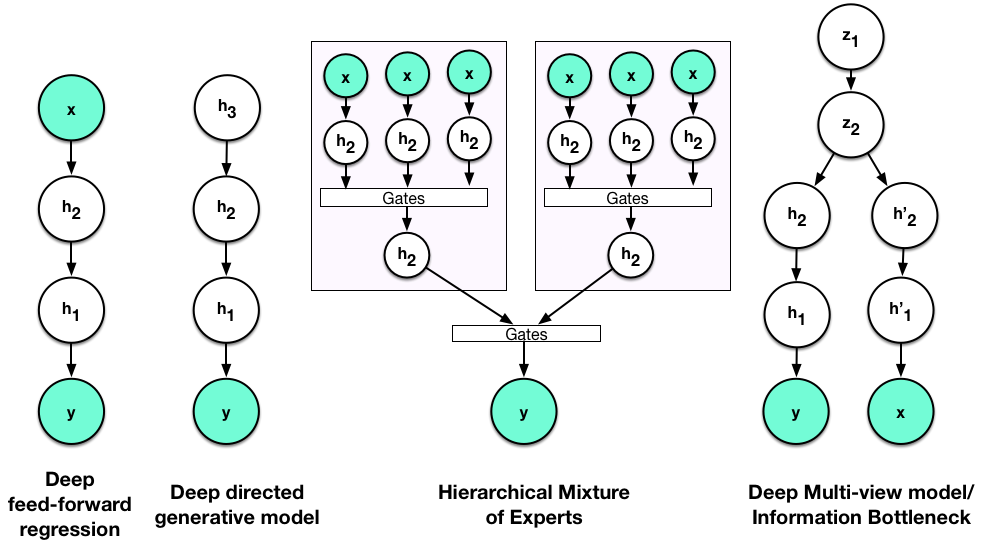
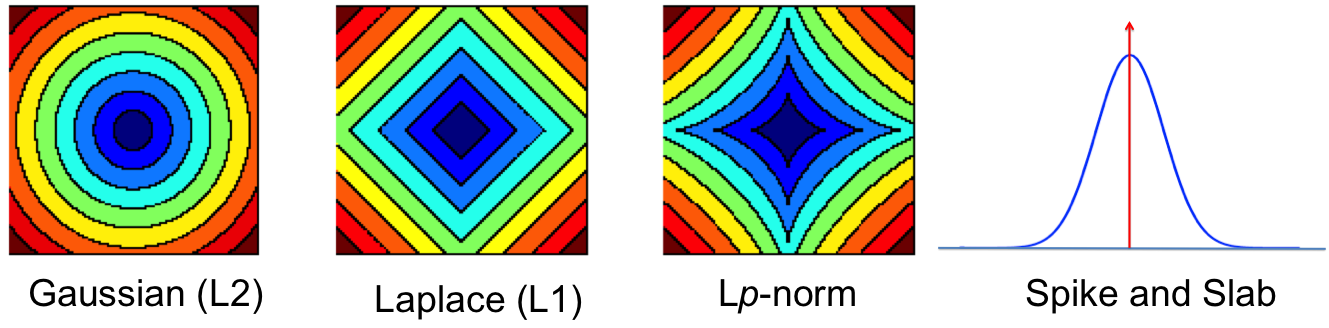
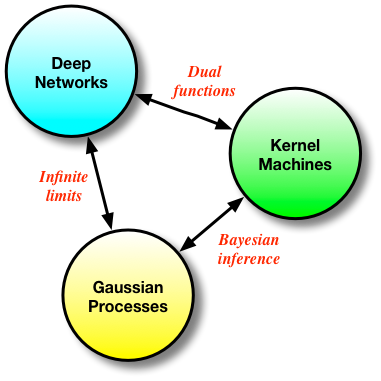
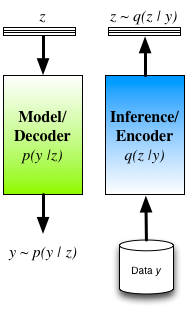
The NIPS 2014 Workshop on Advances in Variational Inference was abuzz with new methods and ideas for scalable approximate inference. The concluding event of the workshop was a lively debate with David Blei, Neil Lawrence, Zoubin Ghahramani, Shinichi Nakajima and Matthias Seeger on the history, trends and open questions in variational inference. One of the questions posed to our panel and audience was: 'what are your variational inference tricks-of-the-trade?'
My current best-practice at present includes: stochastic approximation, Monte Carlo estimation, amortised inference and powerful software tools. But this is a though-provoking question that has has motivated me think in some more detail through my current variational inference tricks-of-the-trade, which are:
Continue reading "Variational Inference: Tricks of the Trade"